

Sora训练与出片
Sora训练与出片
前言:
项目地址: Sora原理与技术实战 - 飞书云文档 (feishu.cn)
代码地址: https://github.com/datawhalechina/sora-tutorial
视频地址:
https://www.bilibili.com/video/BV1kD42177hU/
https://www.bilibili.com/video/BV1Ew4m1d7X2/
参考资料: Stable Video Diffusion(SVD)安装和测试_FMsunyh-GitCode 开源社区 (csdn.net)
一、训练一个sora模型的准备工作,video caption和算力评估
这里实践使用的是魔搭社区开发者复现的modelscope/lite-sora (github.com)后面还会使用Stable Video Diffusion进行实践,一个是txt2vid另一个是img2vid。
1. 使用lite-sora复现sora
首先克隆仓库
git clone https://github.com/modelscope/lite-sora创建虚拟环境
cd lite-sora
conda env create -f environment.ymlbash
conda activate litesoramodels/denoising_model/model.safetensors:这里使用一个小数据集 Pixabay100 训练了一个去噪模型。该模型用于证明我们的训练代码能够正确拟合训练数据,分辨率为 64*64。显然,由于训练数据量有限,该模型存在过拟合,因此现阶段缺乏泛化能力。其目的仅用于验证训练算法的正确性。
# 下载数据集
huggingface-cli download --resume-download ECNU-CILab/lite-sora-v1-pixabay100 --local-dir models --token hf_***然后再训练之前先把pixabay100的视频数据clone下来
git clone https://github.com/ECNU-CILAB/Pixabay100然后进行训练
from litesora.data import TextVideoDataset
from litesora.models import SDXLTextEncoder2
from litesora.trainers.v1 import LightningVideoDiT
import lightning as pl
import torch
if __name__ == '__main__':
# dataset and data loader
dataset = TextVideoDataset("data/pixabay100", "data/pixabay100/metadata.json",
num_frames=64, height=64, width=64)
train_loader = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=1, num_workers=8)
# model
model = LightningVideoDiT(learning_rate=1e-5)
model.text_encoder.load_state_dict_from_diffusers("models/text_encoder/model.safetensors")
# train
trainer = pl.Trainer(max_epochs=100000, accelerator="gpu", devices="auto", callbacks=[
pl.pytorch.callbacks.ModelCheckpoint(save_top_k=-1)
])
trainer.fit(model=model, train_dataloaders=train_loader)这里最大轮数设置的是100000(这里你可以设置的小一点,我跑了11轮就停止了),在训练的时候可以随时查看训练损失
tensorboard --logdir .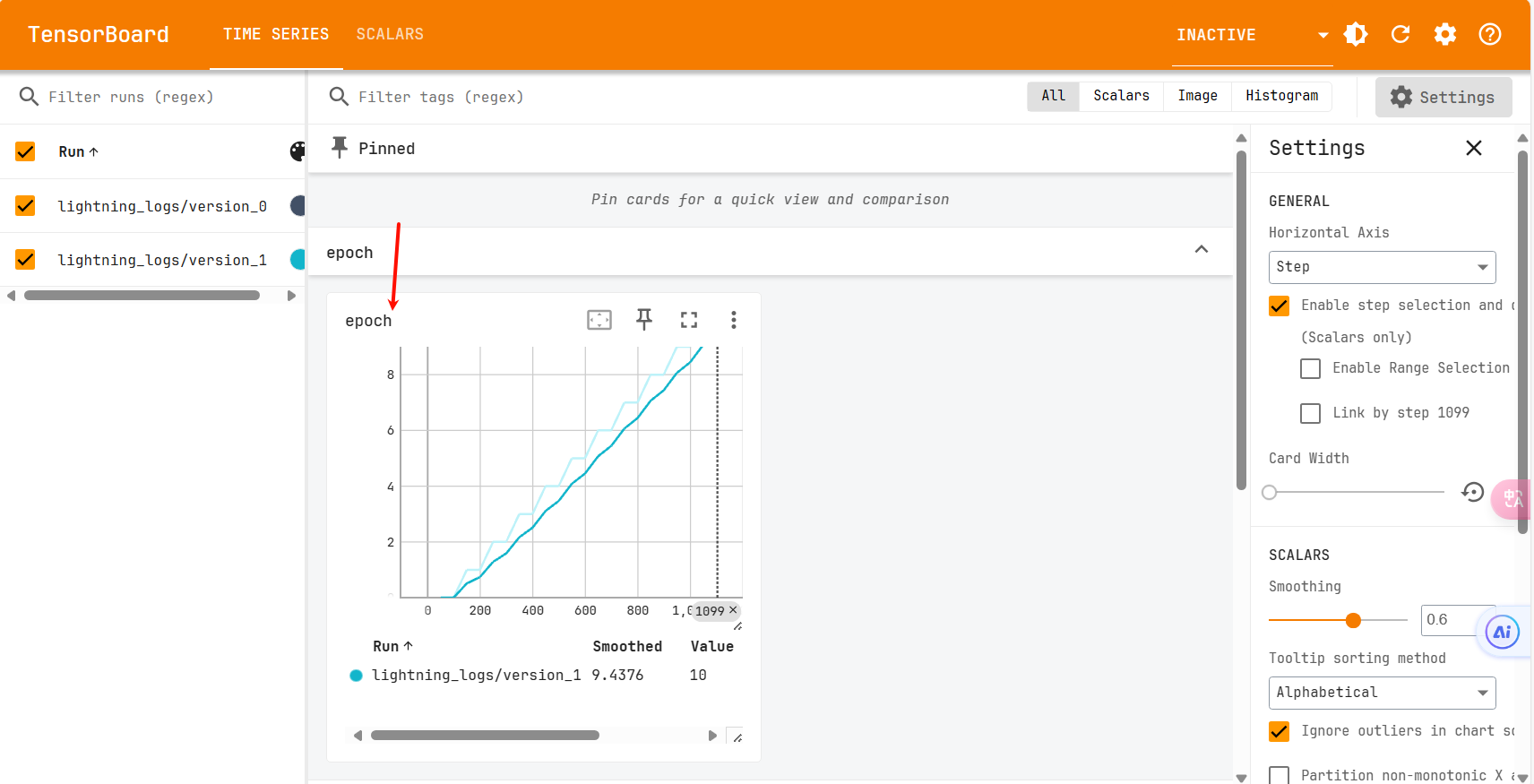
下面进行推理
from litesora.models import SDXLTextEncoder2, VideoDiT
from litesora.pipelines import PixelVideoDiTPipeline
from litesora.data import save_video
import torch
# models
text_encoder = SDXLTextEncoder2.from_diffusers("models/text_encoder/model.safetensors")
denoising_model = VideoDiT.from_pretrained("models/denoising_model/model.safetensors")
# pipeline
pipe = PixelVideoDiTPipeline(torch_dtype=torch.float16, device="cuda")
pipe.fetch_models(text_encoder, denoising_model)
# generate a video
prompt = "woman, flowers, plants, field, garden"
video = pipe(prompt=prompt, num_inference_steps=100)
# save the video (the resolution is 64*64, we enlarge it to 512*512 here)
save_video(video, "output.mp4", upscale=8)我们看一下结果
由于是使用小型数据集 Pixabay100 训练了一个去噪模型。该模型用于证明我们的训练代码能够正确拟合训练数据,分辨率为 64*64。显然,由于训练数据量有限,该模型存在过拟合,因此现阶段缺乏泛化能力。其目的仅用于验证训练算法的正确性。如果有资源的话可以尝试更大的数据集来进行训练。
2. 实践Stable Video Diffusion
大家在实现的时候可以参考Stable Video Diffusion(SVD)安装和测试_FMsunyh-GitCode 开源社区 (csdn.net)这个文章来哦。
实践步骤如下:
下载
git clone https://github.com/Stability-AI/generative-models
cd generative-models下载模型
SVD | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
SVD-XT | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
模型有4个,任意一个都可以使用
环境配置
pip install -r requirements/pt2.txt
pip install .下载两个模型,放在如下的目录下:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.pt
下载地址:
然后运行示例代码:
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 7862如果中间报错了
from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'添加环境变量
echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
source /root/.bashrc运行之后可以看到它支持的四个模型
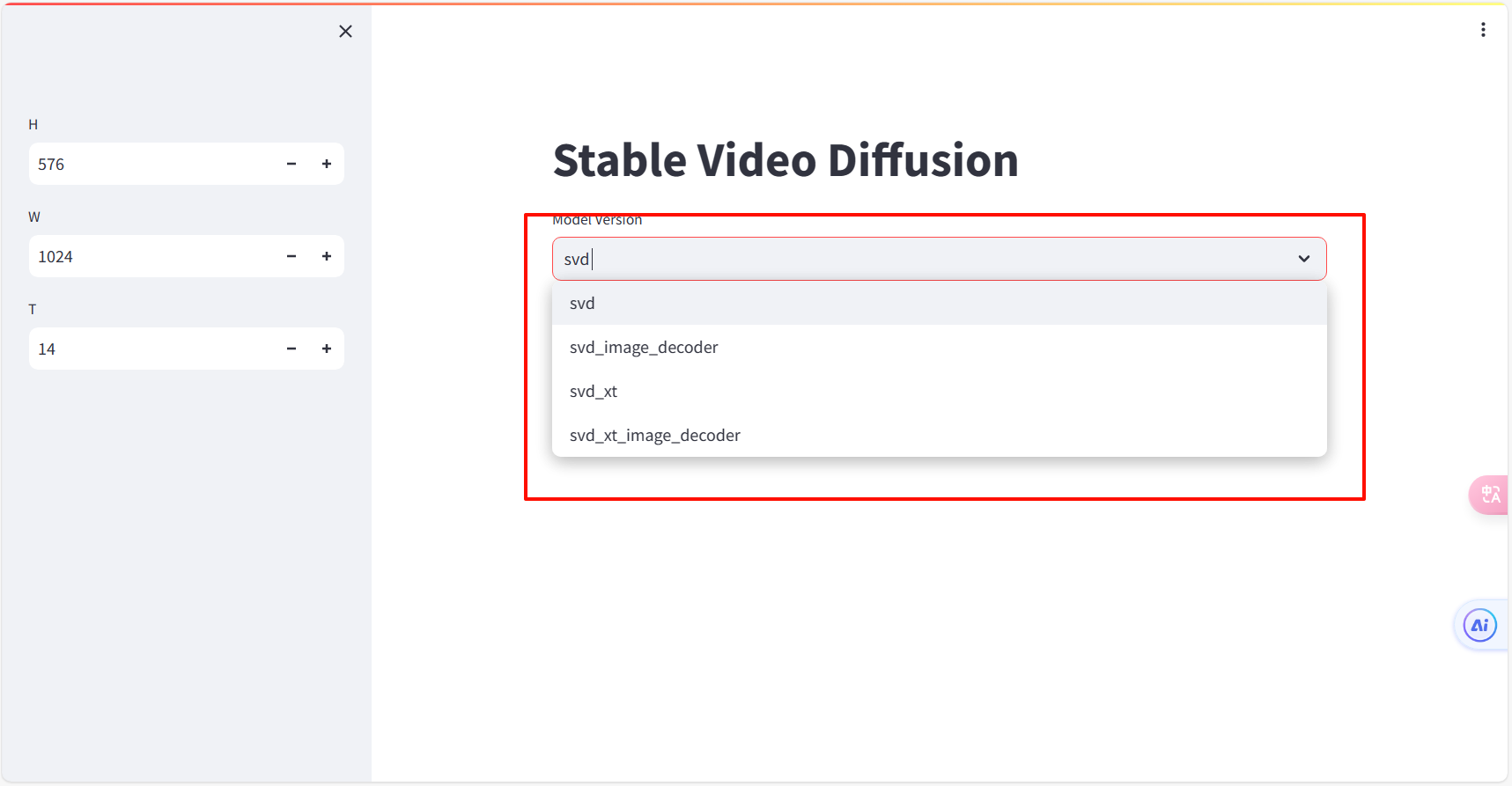
然后上传图片如果遇到上传不上去的可以看一下这个Streamlit 遇到 AxiosError: Request failed with status code 403 错误 (wqmoran.com),解决完以后开始运行

这里我把时间设置成了五秒,因为容易爆显存。
然后你也可以在这个体验地址上面体验Stable Video Diffusion 1.1 - a HF Mirror Space by multimodalart (hf-mirror.com)
二、用自己训练的模型,做一个自己的AI短片吧
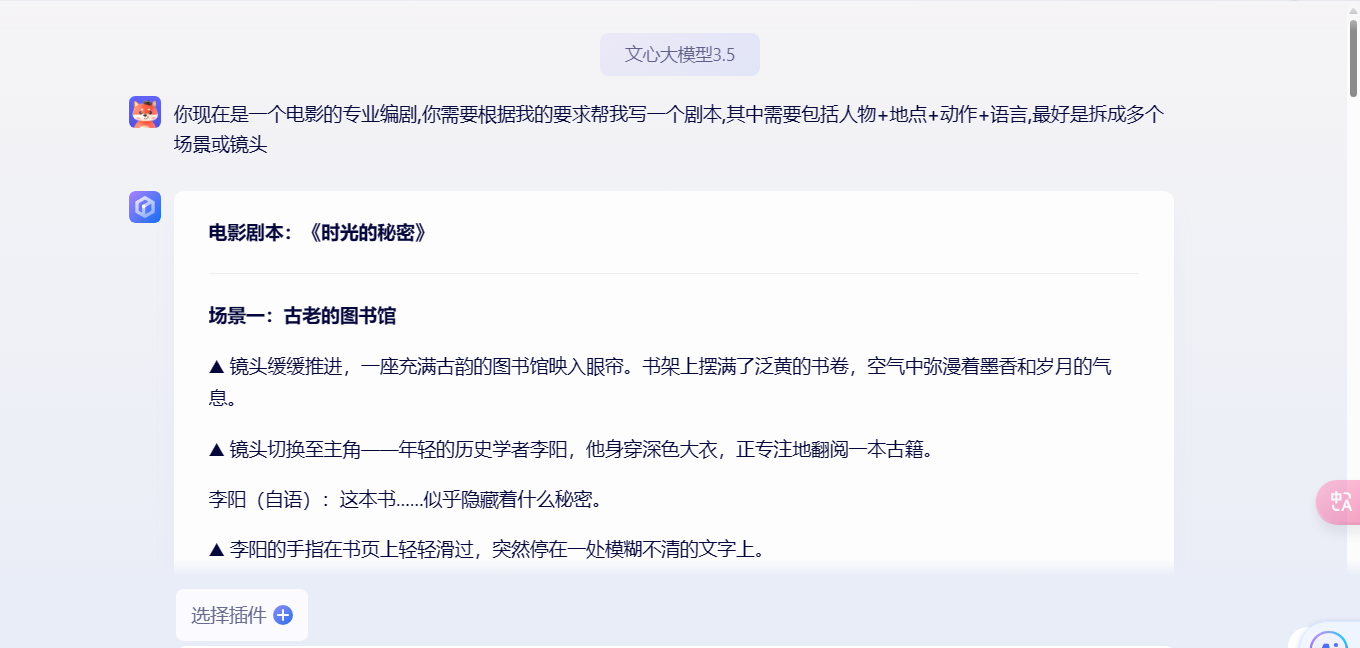
这里的话我使用了Stable Video生成视频,然后短片文章是用文心一言 (baidu.com)生成的。
先生成剧本然后将中文转为应为的prompt
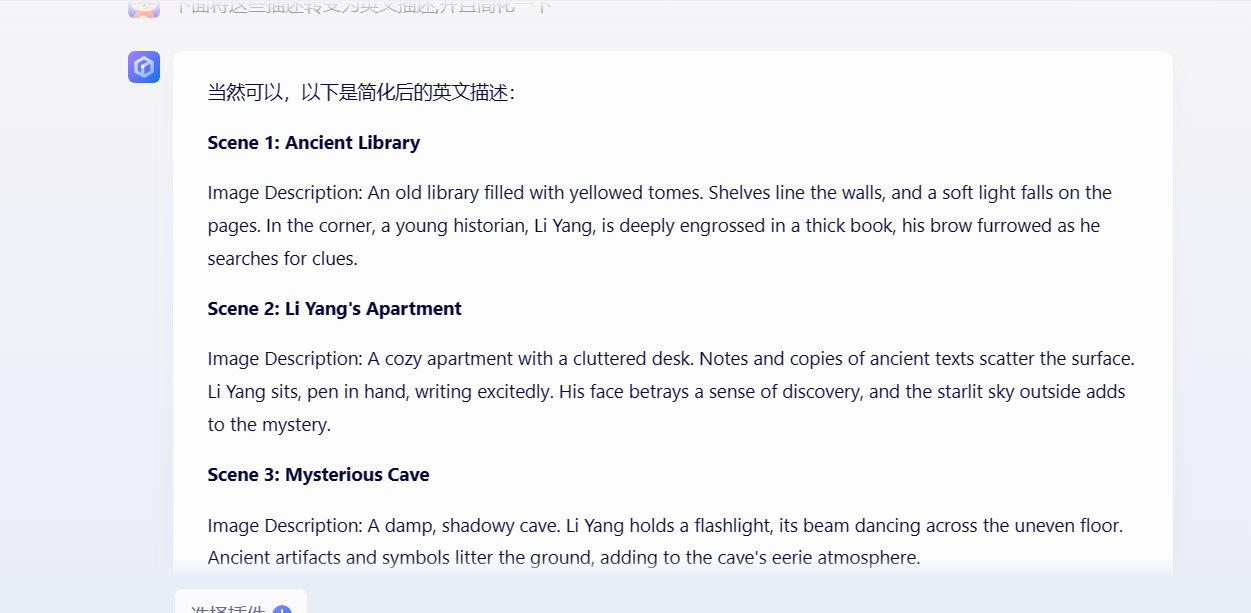
接着使用Stable Video生成图片

过程比较多就不说了,最后使用剪映拼在一起。最后我们看一下成品。
做的不好大家见谅嘿嘿🤭
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
