什么是大语言模型
这一节简单学习一下什么是大语言模型,以及大语言模型的发展历程,还有它所应用的场景。
首先来了解一下什么是大语言模型
一、大语言模型的概述
大语言模型(Large Language Model,LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。通常,LLM 是指包含数千亿(或更多)参数的 Transformer 语言模型,这些模型是在大规模文本数据上进行训练的 , 例如 GPT-3 ,PaLM ,Galactica 和 LLaMA 。 LLM 展现了理解自然语言和解决复杂任务(通过文本生成) 的强大能力。
1.大语言模型的发展历程
目前,LLM 主要建立在 Transformer 架构上,其中多头注意力层堆叠在非常深的神经网络中。 现有的 LLM 采用类似的 Transformer 架构和与小型语言模型相同的预训练目标(如语言建模)。然而,LLM 大幅度扩展 了模型规模、数据规模和总计算量(数量级)。
那大语言模型是怎样发展过来的呢? 其实在
2.大语言模型的参数量大小
如果要说LLM的参数量有多大我只能告诉你很大,因为不同模型的训练数据的数据量是不一样的,这里来看一张图
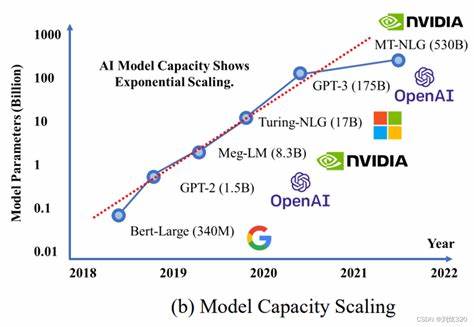
这里少了GPT-1,GPT-1的参数量达1.17亿,预训练的数据量约5GB,从发展阶段来看大语言模型的参数量是越来越大的,这就意味之大语言模型的能力也是越来越好的。