

NEW B 排序三人组
NEW B 排序三人组
1.快速排序
快速排序的思想是从待排序列中取出一个数作为中间数,将比他小的数都排到这个数的左边,比它大的数排到这个数的右边.
首先我们要先实现交换位置的函数,首先我们需要定义一个边界也就是我们待排序列的开始指向left 和末尾指向right ,我们先用一个变量tmp 存储我们要比较的数值,最后当我们比较完以后,再将这个元素归位,我们有一个循环条件就是开始下标要比末尾下标大,
在这个条件下实现如下视频所示:
这个函数实现的是一次的排序,第一次排序完以后我们left 左边是比它小的数,右边是比它大的数.
那我们要再对left 左边的序列和右边的序列在进行快速排序,以此类推,每做完一次都需要将左右两部分进行快速排序,直到left=right 那么这时候就用到了递归.
实现如下:
def partition(li, left, right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp: # 从右面找比tmp小的数
right -= 1 # 往左走一步
li[left] = li[right] # 把右边的值写到左边的位置
while left < right and li[left] <= tmp: # 从左面找比tmp大的数
left += 1
li[right] = li[left] # 把左边的值写到右边的位置
li[left] = tmp # 将tmp归位
return left
def quick_sort(li, left, right):
if left < right:
mid = partition(li, left, right)
quick_sort(li, left, mid - 1)
quick_sort(li, mid + 1, right)
return li对于快速排序,它能很快的排序完成,但是他有一个缺点就是如果待排序列为: 9,8,7,6,5,4,3,2,1 你取到第一个元素那他右边的都要往左移,就成了8,7,6,5,4,3,2,1 ,那这个8后面的也都要往左移,那他的时间复杂度就会提高,本来他的时间复杂度是O(nlogn) ,这就变成了O(n^2) ,解决方法就是第一个元素和后面任意一个元素交换.
2.堆排序
要了解堆排序的原理,要先了解树,树是一种常见的数据结构,那么堆就是完全二叉树,什么是完全二叉树.
完全二叉树是由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
那么堆又分为大顶堆和小顶堆(或大根堆和小根堆),
性质:
每个结点的值都大于其左孩子和右孩子结点的值,称之为大根堆;每个结点的值都小于其左孩子和右孩子结点的值,称之为小根堆。
如下图
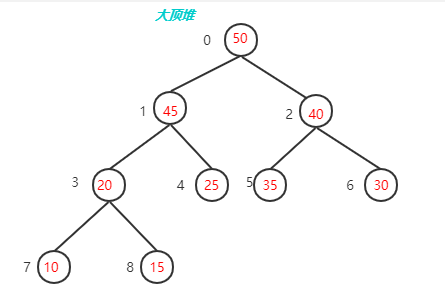
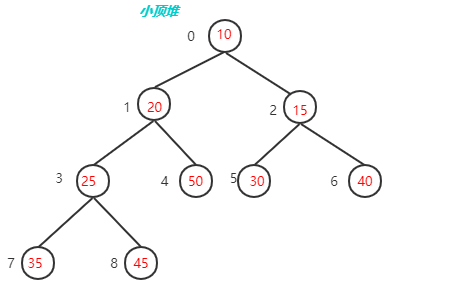
要想实现堆排序要先实现建立堆的操作,因为我们用列表实现的所以我们要先找父节点的下标和子节点的下标,假如父节点是i,那子节点就分别是2*i+1和2*i+1,你可以根据上面的图推导一下
下面可以看一个视频来理解一下:
看完以后不知道你是否清楚了堆排序的原理.
下面基于大顶堆的堆排序代码:
def sift(li, low, high):
"""
:param li: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return:
"""
i = low # i是指向n节点
j = 2 * i + 1 # j开始是左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有数
if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子有并且比较大
j = j + 1 # j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j # 往下看一层
j = 2 * i + 1
else: # tmp更大, 把tmp放到i的位置上
break
li[i] = tmp因为堆是许多的小堆建立起来的,所有我们要将所有的小堆合起来
def heap_sort(li):
n = len(li)
for i in range((n-2)//2 , -1, -1):
# i表示建堆的时候调整的部分堆顶的下标
sift(li, i, n-1)
# 建堆完成
for i in range(n-1, -1 ,-1):
# i指向当前堆的最后一个元素
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1) # i-1是新的high
return li堆建立完以后再进行交换
堆排序中有一个很好的问题就是topk问题,意思就是从一个序列中选出k个最大的元素来,它可以用堆排序来解决.
因为topk问题是基于小顶堆来实现的只需要将上面堆排序的li[j+1] > li[j]和li[j] > tmp改成小于号就行.
代码如下:
def sift(li, low , high):
"""
:param li: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return:
"""
i = low # i是指向n节点
j = 2 * i + 1 # j开始是左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有数
if j + 1 <= high and li[j+1] < li[j]: # 如果右孩子有并且比较大
j = j + 1 # j指向右孩子
if li[j] < tmp:
li[i] = li[j]
i = j # 往下看一层
j = 2 * i + 1
else: # tmp更大, 把tmp放到i的位置上
break
li[i] = tmp
def topk(li, k):
heap = li[0:k]
for i in range((k-2)//2, -1, -1):
sift(heap, i, k-1)
# 1.建堆
for i in range(k, len(li)-1):
if li[i] > heap[0]:
heap[0] = li[i]
sift(heap, 0, k-1)
# 2.遍历
for i in range(k-1, -1 ,-1):
heap[0], heap[i] = heap[i], heap[0]
sift(heap, 0, i - 1)
# 3.出数
return heap3.归并排序
归并排序的原理和快速排序有点像,它是将一个序列先分解再合并,合并好的两个有序序列比较,小的存到新的列表中,这样比较下去
如下图

代码如下:
def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high: # 只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
# while执行完, 肯定有一部分没有数了
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp完成排序以后再将排序好的替换到原来的列表中
和快速排序一样,先递归左边在递归右边,最后再归并
def merge_sort(li, low, high):
if low < high: # 至少有两个元素, 递归
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid+1, high)
merge(li, low, mid, high)上面所出示的代码都有一些注释,一定要理解清楚,而且要自己把代码敲一遍.
因为三个排序的时间复杂度都是O(nlogn)除了其他特殊情况,相比于前面说的三种排序快了不少,所以它们被称为NEW B 排序三人组.
而且三种排序方式的也有快慢之分快速排序<归并排序<堆排序.
其实python中的sort()函数是基于归并排序和快速排序优化写成的,所以他的排序效率是非常快的,下次我们来说一下其他四种排序希尔排序,计数排序,桶排序和基数排序.
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
