

书生·浦语大模型全链路开源体系-笔记
书生·浦语大模型全链路开源体系
视频地址: 书生·浦语大模型全链路开源体系
✍总结:
在这一视频中介绍了大模型全链路开源体系。大模型已成为热门关键词,在学术界和工业界都有广泛研究和应用。
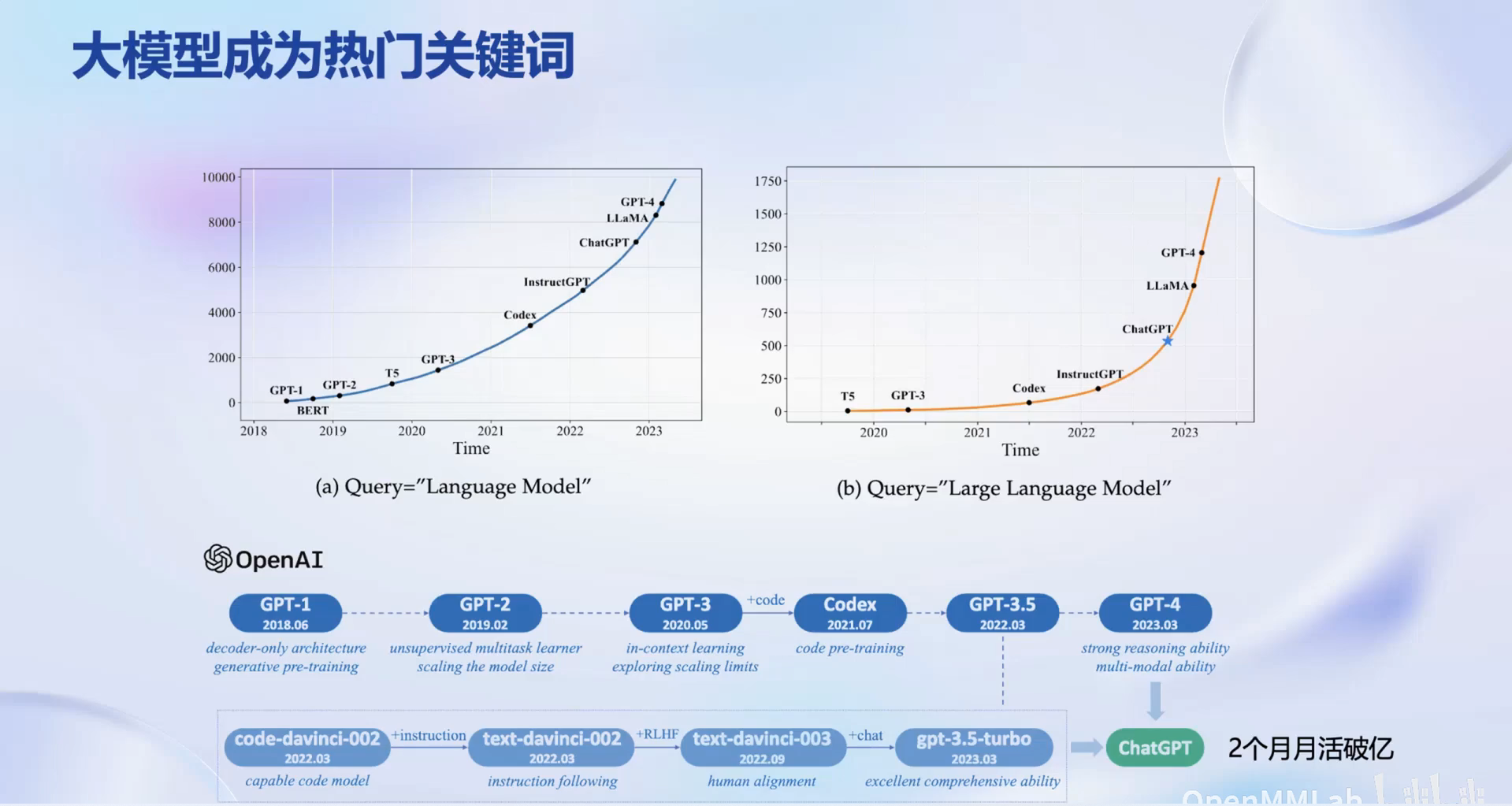 大模型是发展人工
大模型是发展人工通用人工智能的重要途径,一个模型应对多种任务和多种模态,提升模型的通用性。
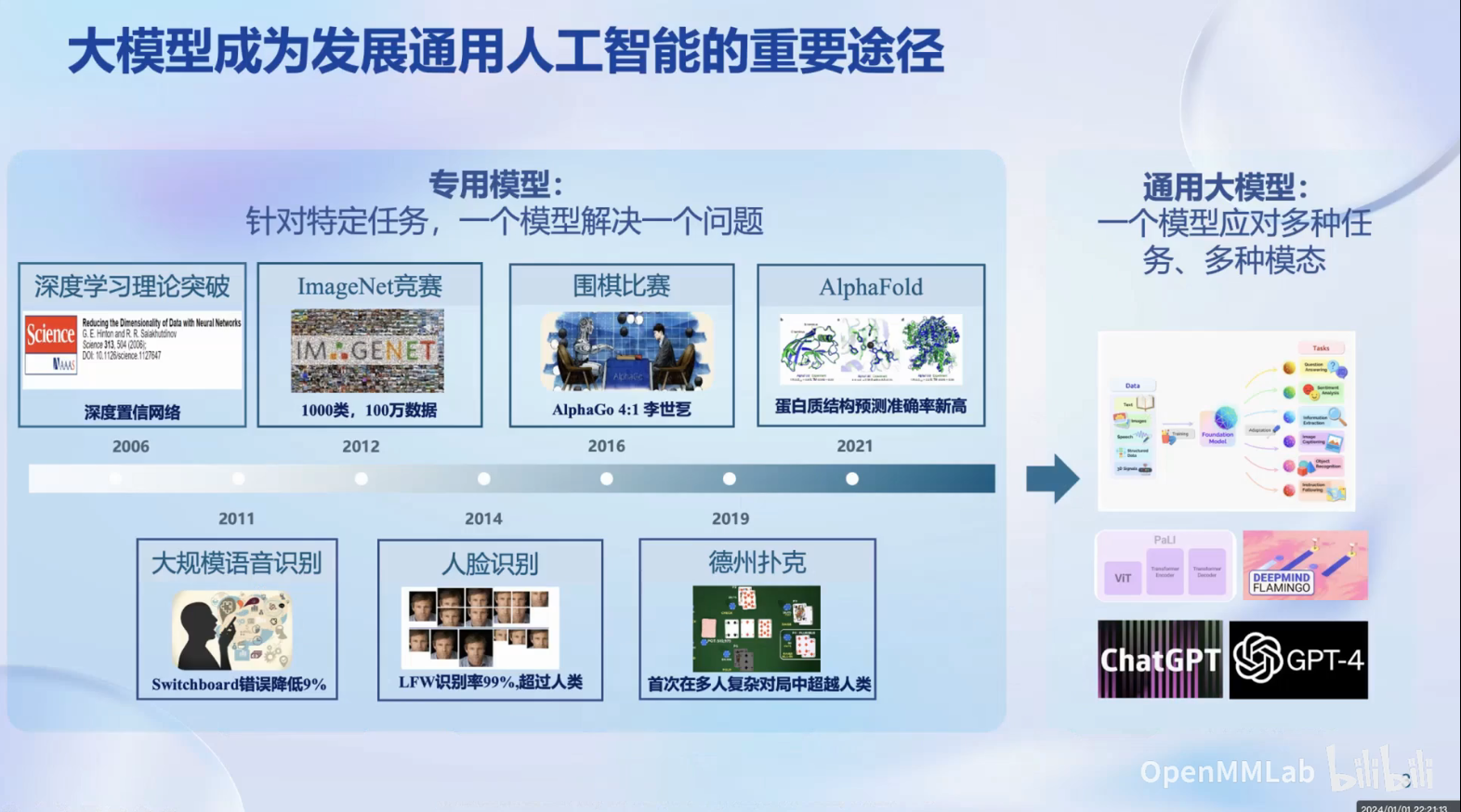 上海人工程实验室投入大量研究力量进行大语言模型以及大模型的研发工作,持续推进大模型的开源。实验室发布了千亿参数的大模型,进行了全面升级,并开源了全链条的工具体系。这是
上海人工程实验室投入大量研究力量进行大语言模型以及大模型的研发工作,持续推进大模型的开源。实验室发布了千亿参数的大模型,进行了全面升级,并开源了全链条的工具体系。这是书生·浦语大模型的发展历程:
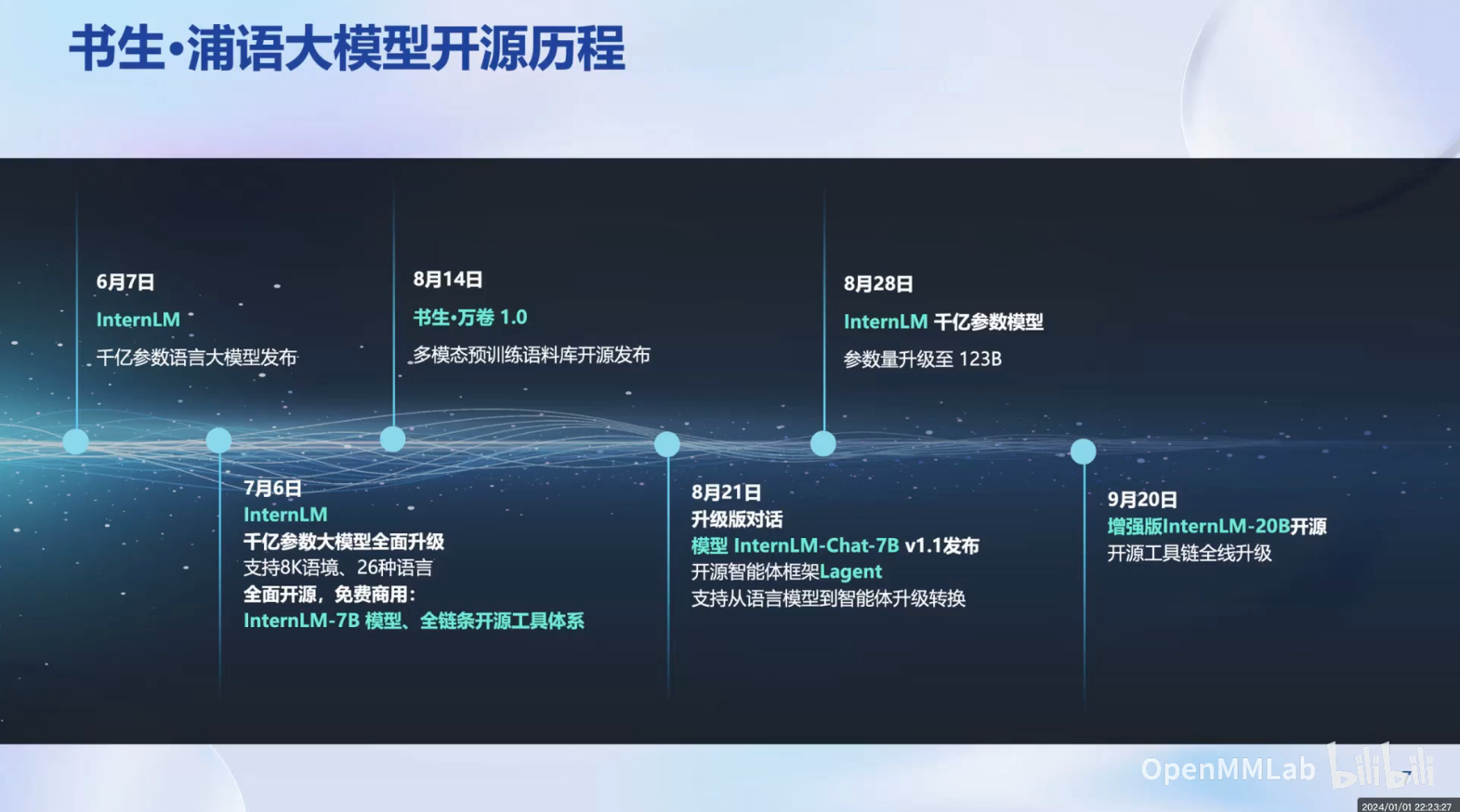
书生·浦语的大模型已完成覆盖轻量级、中量级、重量级的系列,为社区的开发者和企业提供优质的模型。7B参数的模型方便部署,是低成本可用的最佳规模;20B参数的模型提供开发定制高精度的小模型规模;123B参数的模型具备强大性能,提供全面的优势。
 这些开源可用的模型将为社区的开发者和企业提供优质的模型。
这些开源可用的模型将为社区的开发者和企业提供优质的模型。
下面就进一步探讨了从专用模型到通用模型的发展历程。
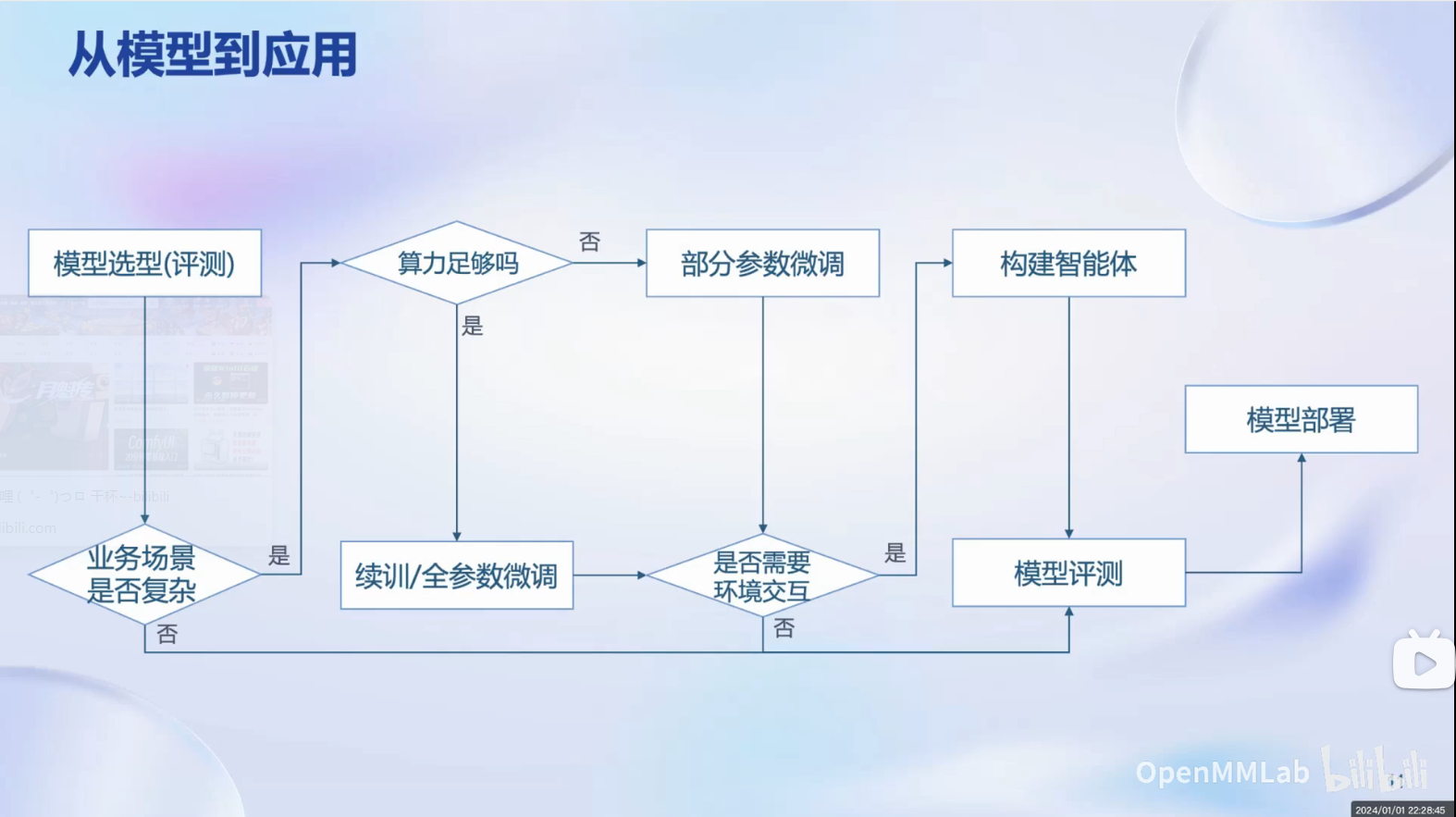 它提到了深度学习在语音识别、图像识别等领域的应用,以及这些领域中的专用模型设计。
它提到了深度学习在语音识别、图像识别等领域的应用,以及这些领域中的专用模型设计。
接下来进一步介绍了书生·浦语全链开源开放体系 ,其中包括数据(书生·万卷)、预训练(InternLM-Train)、微调(XTuner)、部署(LMDeploy)、评测(OpenCompass)和应用(Lagent和AgentLego)
 在
在数据层面通过2TB的数据在其中做了多模态融合、精细化处理还有价值观对齐 。

 在
在预训练中做到了高可扩展、极致性能优化、兼容主流和开箱即用 。
 在
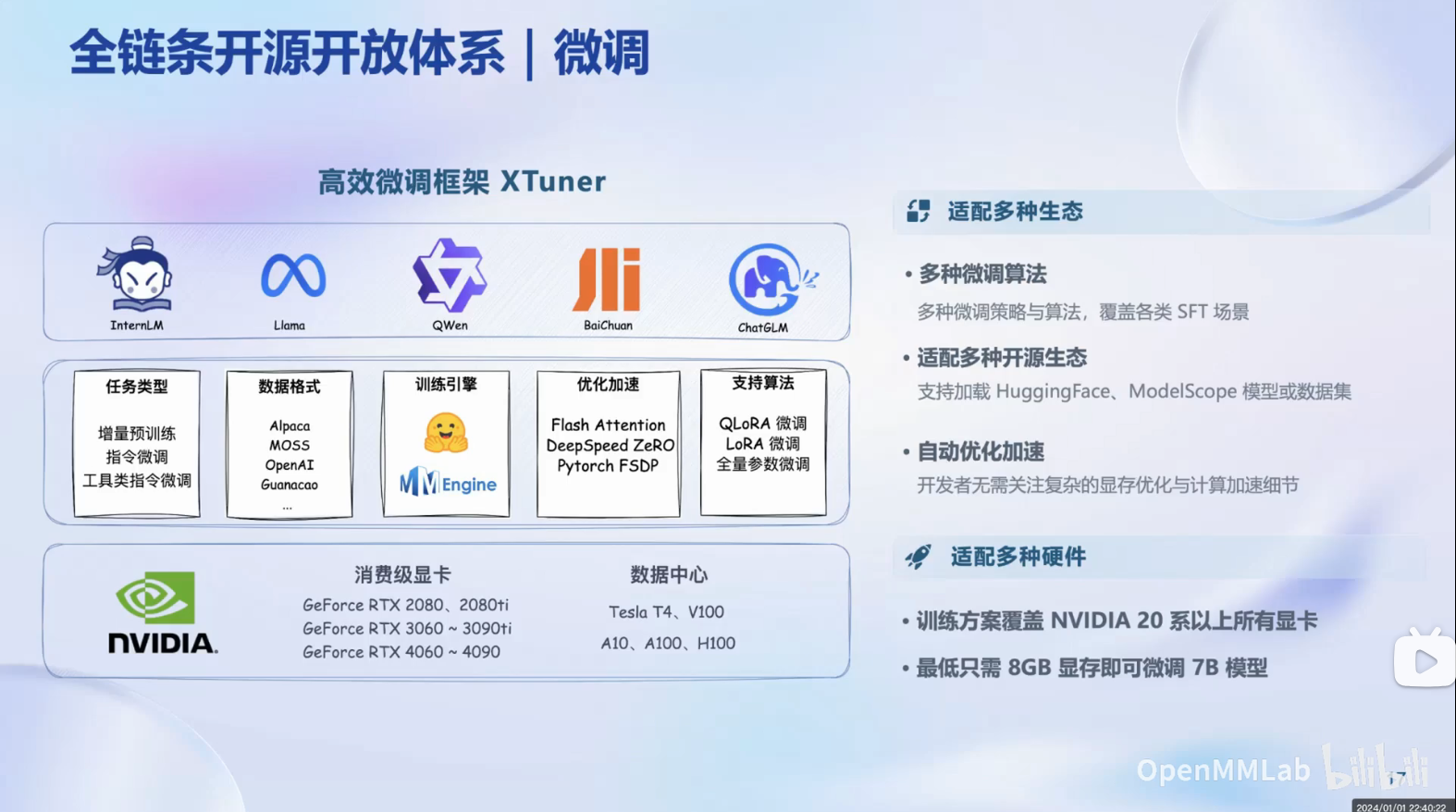
在微调中包括以下内容

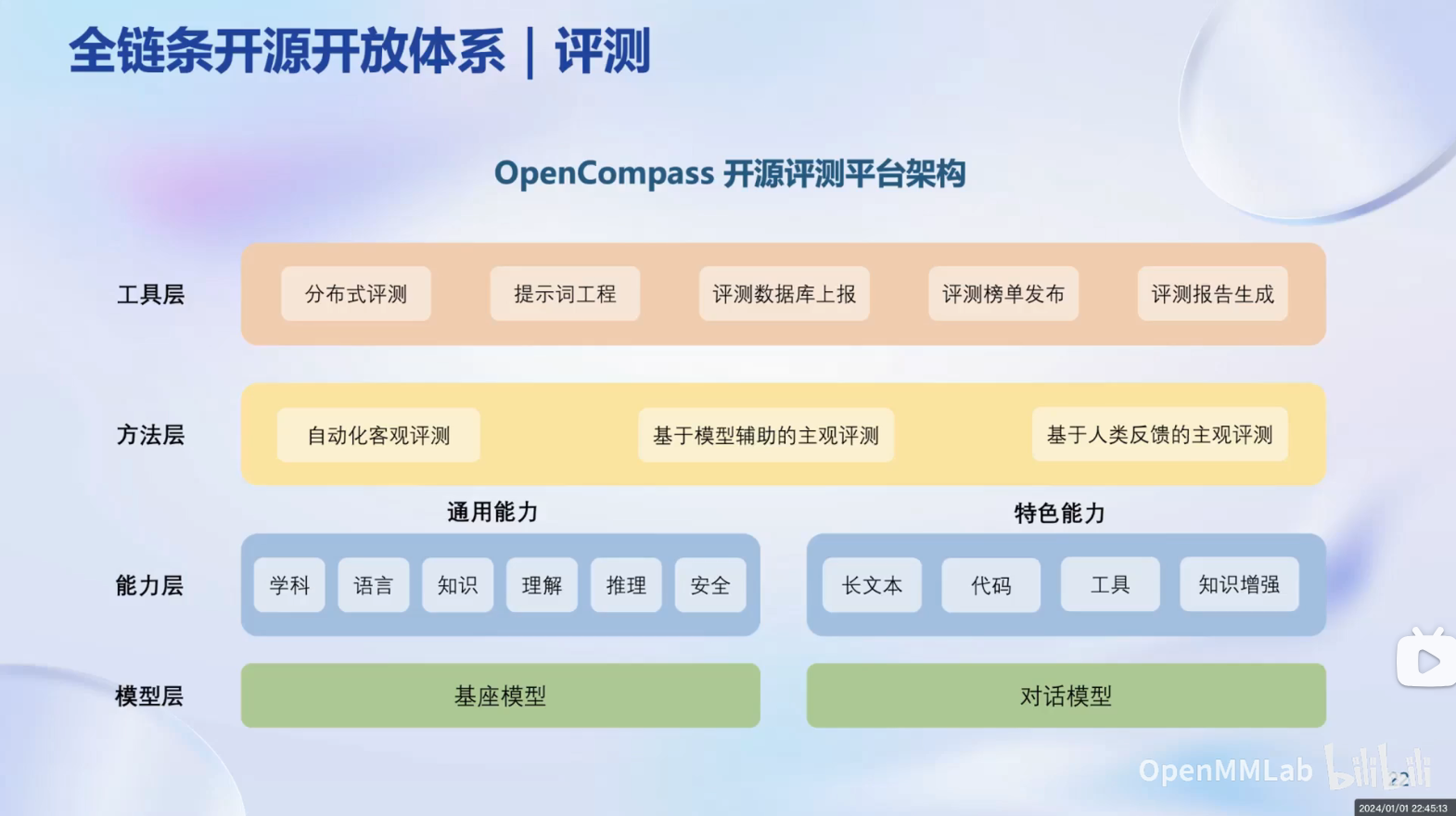
评测 的内容主要针对数据进行处理,让他能够实现更高的维度

部署中讲了现在大语言模型的特点以及遇到的技术挑战然后针对这些做的部署方案,其中介绍了LMDeploy 的一些特点


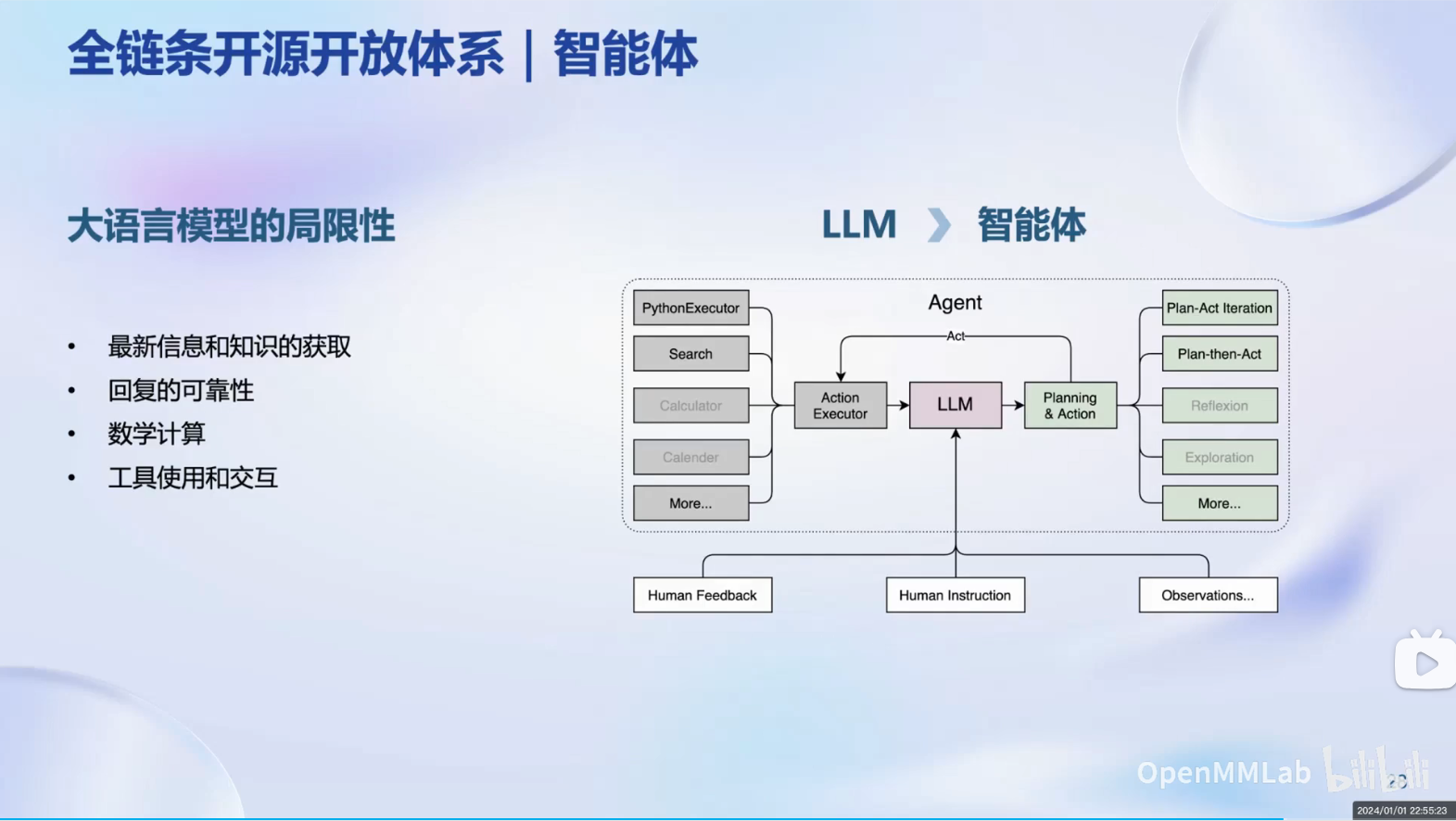
智能体通常指的是一个能够自主行动并与环境进行交互的系统或实体。在智能体的研究中,涉及了多个方面和主题
 这就是本节讲到的书生·浦语大模型全链路开源体系的一些主要内容。
这就是本节讲到的书生·浦语大模型全链路开源体系的一些主要内容。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
