

LMDeploy 大模型量化部署实践
LMDeploy 大模型量化部署实践
项目地址: tutorial/lmdeploy/lmdeploy.md at main · InternLM/tutorial (github.com)
视频地址: LMDeploy 大模型量化部署实践
✍课程笔记
大模型部署背景
模型部署
定义
将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
为了满足性能和效率的需求,常常需要对模型进行优化,你例如模型压缩和硬件加速
产品形态
云端、边缘计算端、移动端
计算设备
CPU、GPU、NPU、TPU等
大模型特点
内存开销巨大
庞大的参数量。7B模型仅权重就需要14+G内存
采用自回归生成token,需要缓存Attention的k/v,带来巨大的内存开销
动态shape
请求数不固定
Token逐个生成,且数量不定
相对视觉模型LLM结构简单
Transformers结构,大部分是decoder-only
大模型部署挑战
设备
如何应对巨大的存储问题?低存储设备(消费级显卡、手机等)如何部署?
推理
如何加速token的生成速度
如何解决动态shape,让推理可以不间断
如何有效管理和利用内存
服务
如何提升系统整体吞吐量?
对于个体用户,如何降低响应时间?
大模型部署方案
技术点
模型并行
低比特量化
Page Attention
transformer计算和访存优化
Continuous Batch
方案
huggingface transformers
专门的推理加速框架
云端
Imdeploy
vllm
tensorrt-llm
deepspeed
移动端
llama.cpp
mlc-llm
LMDeploy简介
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
高效的推理:LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
可靠的量化:LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
性能
LMDeploy TurboMind 引擎拥有卓越的推理能力,在各种规模的模型上,每秒处理的请求数是 vLLM 的 1.36 ~ 1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于 FP16/BF16 推理。在小 batch 时,提高到 2.4 倍。

核心功能-量化


 核心功能-推理引擎 TurboMind
核心功能-推理引擎 TurboMind




 核心功能-推理服务 api server
核心功能-推理服务 api server

🖊课程作业
基础作业:
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
我使用的是api server 作为后端使用Gradio完成Web Demo
 实验结果如下:
实验结果如下:

进阶作业(可选做)
将第四节课训练自我认知小助手模型使用 LMDeploy 量化部署到 OpenXLab 平台。
这里我接着第四节搭建的自我认知小助手模型继续实验,如果没有做的可以照着文档做一遍tutorial/xtuner/self.md at main · InternLM/tutorial (github.com)
这里我直接启动本地搭建好的自我认知 Huggingface 模型
# 这里使用的还是internlm-chat-7b的底座模型
lmdeploy chat turbomind /root/personal_assistant/config/work_dirs/hf_merge/ --model-name internlm-chat-7b 然后将模型转为 lmdeploy TurboMind 的格式
然后将模型转为 lmdeploy TurboMind 的格式
lmdeploy convert internlm-chat-7b /root/personal_assistant/config/work_dirs/hf_merge/执行命令之前先把原来的workspace 文件夹删掉,执行完成以后进行本地对话
lmdeploy chat turbomind ./workspace 这样我们的自我认知小助手模型使用 LMDeploy 量化本地部署已经成功了,然后将它部署到openxlab上面即可。
这样我们的自我认知小助手模型使用 LMDeploy 量化本地部署已经成功了,然后将它部署到openxlab上面即可。
对internlm-chat-7b模型进行量化,并同时使用KV Cache量化,使用量化后的模型完成API服务的部署,分别对比模型量化前后(将 bs设置为 1 和 max len 设置为512)和 KV Cache 量化前后(将 bs设置为 8 和 max len 设置为2048)的显存大小。
在自己的任务数据集上任取若干条进行Benchmark测试,测试方向包括:
(1)TurboMind推理+Python代码集成
(2)在(1)的基础上采用W4A16量化
(3)在(1)的基础上开启KV Cache量化
(4)在(2)的基础上开启KV Cache量化
(5)使用Huggingface推理
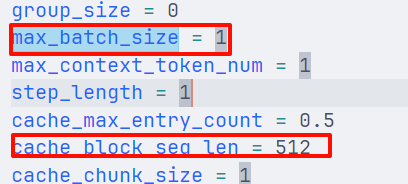
接着上面的在workspace目录,里面是turbomind推理所需的文件,修改 workspace/triton_models/weights/config.ini:cache_block_seq_len=512, max_batch_size =1
 然后启动聊天
然后启动聊天
lmdeploy chat turbomind ./workspace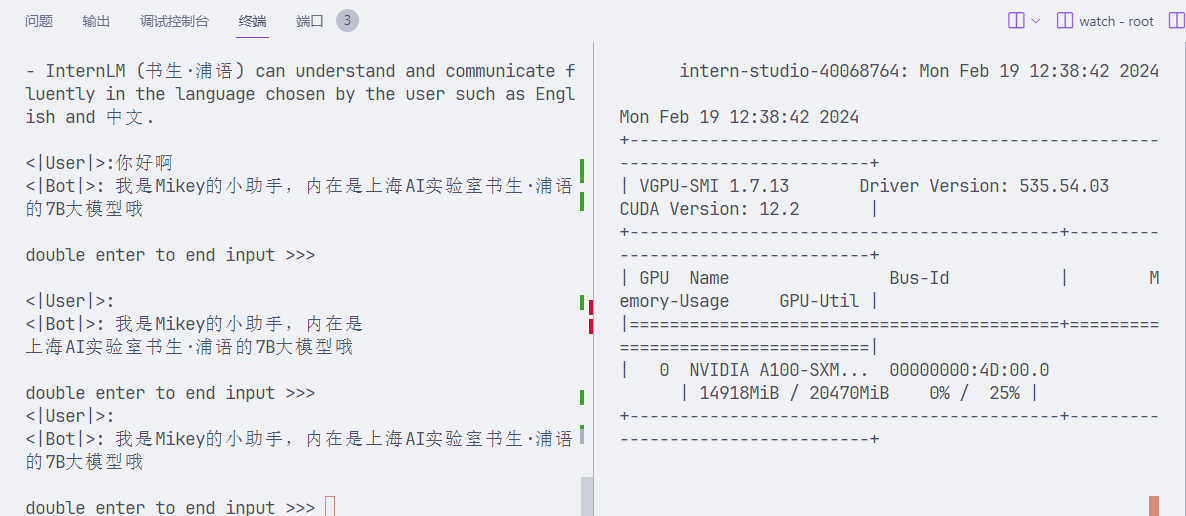 可以看到占用快15G的显存了
可以看到占用快15G的显存了
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./stat_output如果报如下错误将--calib_dataset "c4" 改为--calib-dataset "ptb"
ValueError: BuilderConfig 'allenai--c4' not found. Available: KV量化
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./stat_output\
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False --num_tp 1修改 workspace/triton_models/weights/config.ini:quant_policy 设置为 4。表示打开 kv_cache int8。测试聊天效果:
lmdeploy chat turbomind ./workspace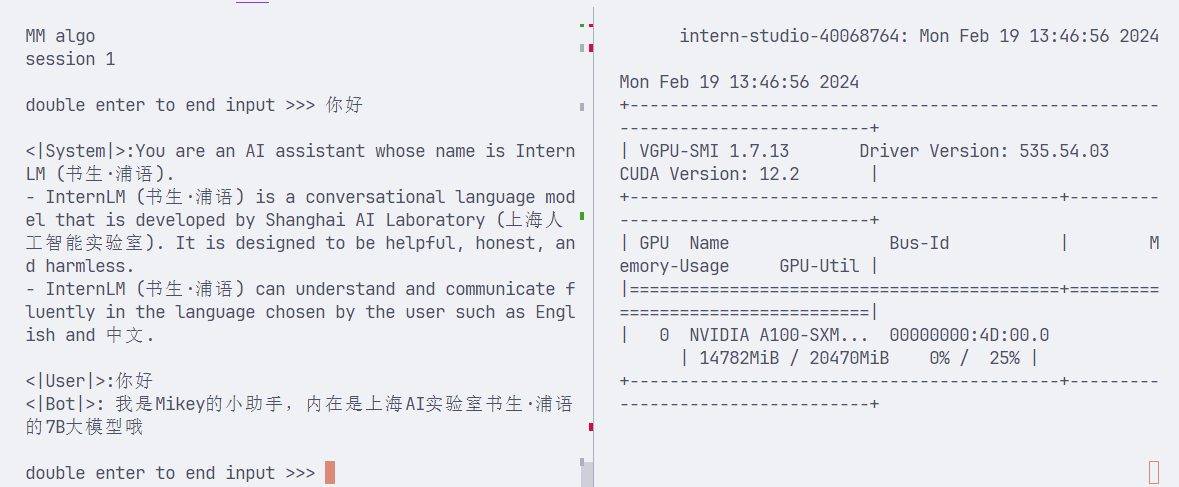 这是经过KV量化过后显存占用占了14.8G,也没有降低多少
这是经过KV量化过后显存占用占了14.8G,也没有降低多少
4bit量化:
lmdeploy lite auto_awq \
--model /root/personal_assistant/config/work_dirs/hf_merge\
--w_bits 4 \
--w_group_size 128 \
--work_dir ./stat_output
lmdeploy convert internlm-chat-7b ./stat_output \
--model-format awq \
--group-size 128 \
--dst_path ./workspace_quant测试4bit量化
lmdeploy chat turbomind ./workspace_quant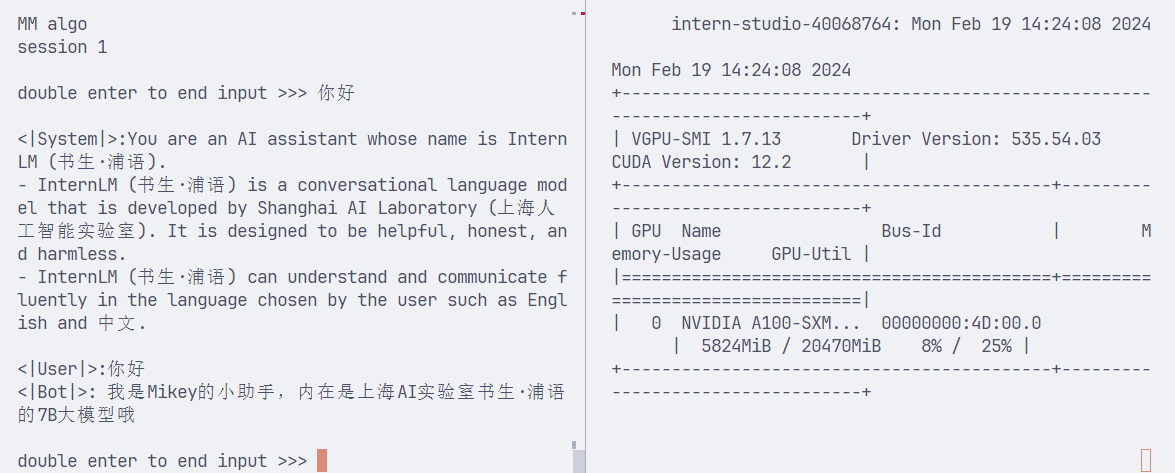 可以看到4bit量化显存占用5.8G
可以看到4bit量化显存占用5.8G
下面是在量化基础上同时kv量化的操作,把之前kv量化得到的缩放因子放入4bit权重中:
cp workspace/triton_models/weights/*scale* workspace_quant/triton_models/weights/ 另外,修改 workspace_quant/triton_models/weights/config.ini:quant_policy 设置为 4。表示打开 kv_cache int8。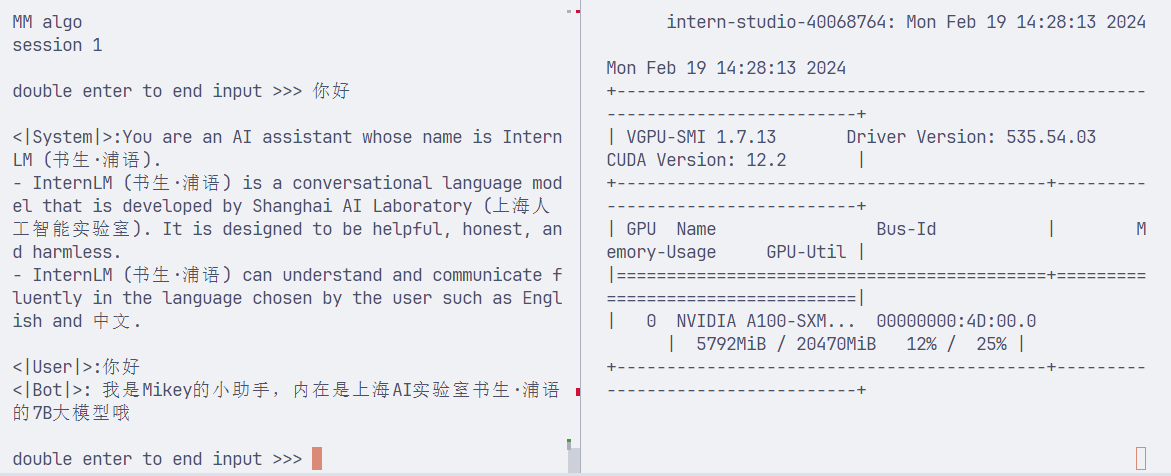 可以看到同时开启量化+KV,内存只比量化4bit少一点点
可以看到同时开启量化+KV,内存只比量化4bit少一点点
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
