

茴香豆:搭建自己的RAG智能助手
茴香豆:搭建自己的RAG智能助手
引言
首先打个广告,非常欢迎大家参与由上海人工智能实验室组织的书生·浦语实战营第二期,在实战营你可以学到什么呢?
🚀 在这次实战营后,你能收获:
下载Huggingface模型并在命令行、网页端运行!堪比本地的文心一言。
实现RAG,让大模型拥有知识库,试试把你的项目文档、pdf资料等给模型参考吧。
实现大模型参数高效微调,角色扮演、音乐生成、食谱编写……只有你想不到,没有你做不到!
实现量化部署模型,让3060能跑7B模型,让你的机器人能调用模型python接口获取回复。
智能体应用搭建,给予模型工具、计划、记忆……让其成为全能助手
跑通大模型评测,学习根据大模型排行榜单挑选适合业务的模型,并熟悉衡量模型好坏的维度指标。
熟悉常用微调数据格式,让平常收集“指令微调”数据与清洗不再困难!
快来和大佬们一起学习吧。感兴趣的给我们InternLM点个小✨
课程地址:https://github.com/InternLM/Tutorial/tree/camp2/huixiangdou
视频地址:https://www.bilibili.com/video/BV1QA4m1F7t4
项目地址:https://github.com/InternLM/InternLM
报名链接:https://www.wjx.cn/vm/tUX8dEV.aspx?udsid=2146
简介
首先我们要知道什么是RAG,以及RAG可以解决的问题:
RAG是Retrieval-Augmented Generation的缩写,即检索增强生成。它是一种结合了信息检索和自然语言生成的技术。RAG的主要思想是通过在生成过程中引入外部知识库或信息源,来增强模型的生成能力。
RAG可以解决以下问题:
幻觉问题:大语言模型在生成过程中可能会出现幻觉,即生成一些与事实不符的内容。通过引入外部知识库,RAG可以帮助模型在生成过程中进行事实核查,减少幻觉的出现。
知识更新:大语言模型的知识通常是基于训练数据的,而这些数据可能已经过时。通过引入外部知识库,RAG可以帮助模型在生成过程中获取最新的知识,从而保持知识的更新。
多模态处理:传统的RAG应用主要基于文本的输入和输出,而多模态RAG应用则可以融合文本和图片的处理能力。这使得RAG在医疗影像诊断、智能客服等领域具有广泛的应用前景,可以结合文本和图像信息提供更全面的辅助诊断或回复。
教育和艺术创作:在教育领域,RAG可以帮助教师更好地解释复杂的概念,通过文字和图片的结合呈现更生动、直观的教学内容。在艺术创作领域,RAG可以为艺术家提供更多样化的创作灵感和工具,通过文本和图片的交互创作出更具表现力的作品。
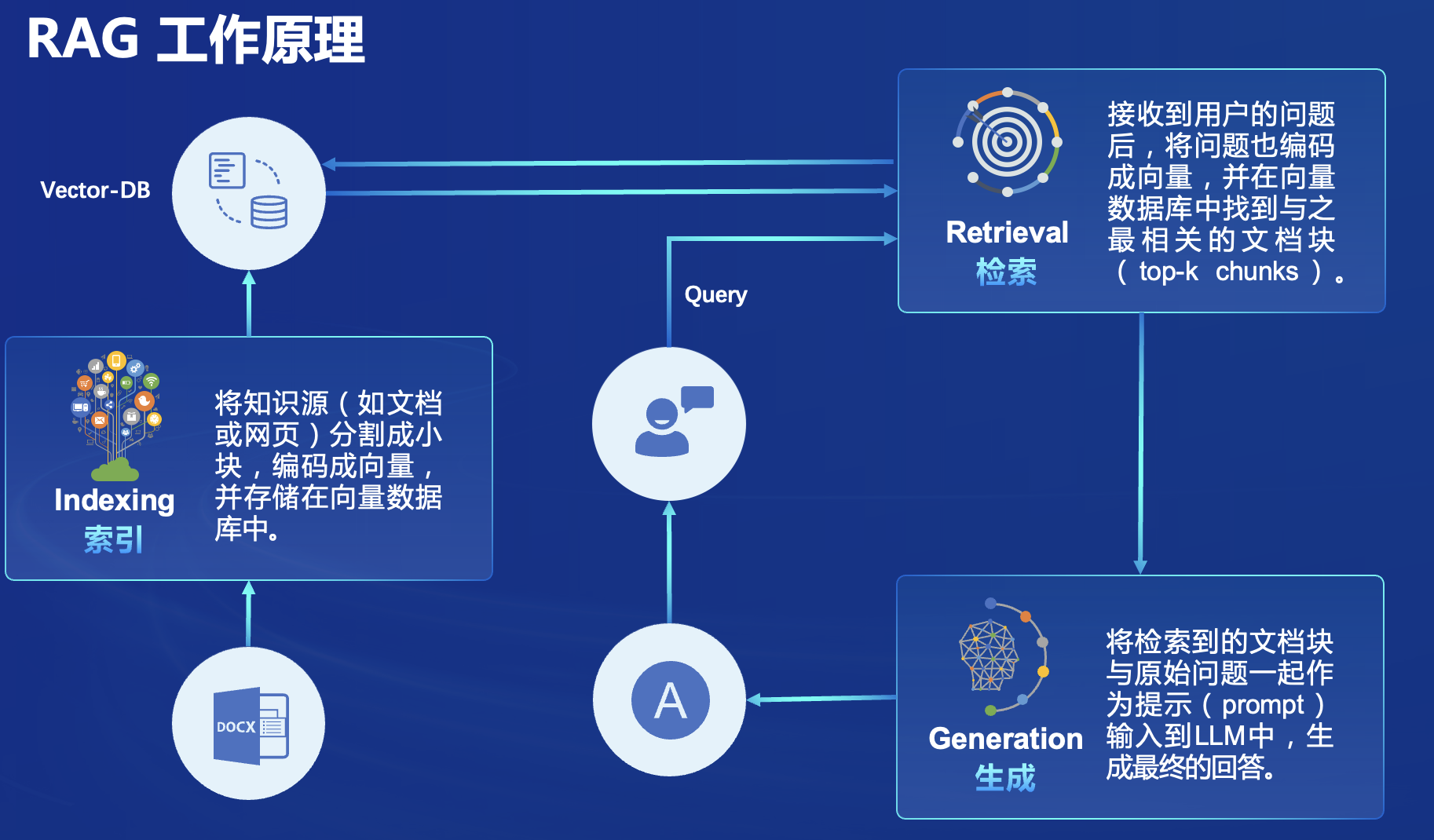
那么RAG是如何工作的呢?
RAG首先将我们的知识源转化为向量数据,然后将这些向量数据存储在向量数据库中,基于用户输入进行信息检索在向量数据库中找到最相关的文档块(top-k chunks),然后将预先设置好的prompt和用户提问一起输入到LLM中,生成最终的回答。
在了解完RAG的相关概念以后,我们来简单说一下RAG与微调(Fine Tune)的区别:
微调的工作流程通常包括以下几个步骤:
预训练:在大规模的语料库上训练一个通用的语言模型,学习语言的一般表示。
任务调整:使用特定任务的数据集对预训练模型进行微调。这通常涉及在模型的顶部添加一些特定于任务的层,并使用反向传播算法来调整模型的参数。
评估:使用独立的测试集评估微调后的模型在特定任务上的性能。
那么对于比较大的数据集来说,由于他需要进行预训练,对算力的要求是非常大的。RAG它可以通过引入外部知识库来增强模型的生成能力,而微调比较适合来做特定任务。
这样可以看出RAG更适合在垂直领域上面的一些工作。
微调(Fine-tuning)是一种在预训练模型的基础上进行进一步训练的方法。它通常用于将一个在大规模数据集上预训练的通用模型(如BERT、GPT)调整为适应特定任务的模型。
这里我们先了解到这里,关于RAG的知识我以后会专门出一个专题来讲,大家注意留意我的博客哦~
基础作业
关于基础作业部分按照课程里面做是没有问题的,但是会遇到一些小问题,下面我会展示我运行的结果和如何解决遇到的问题。
1. 运行茴香豆知识助手
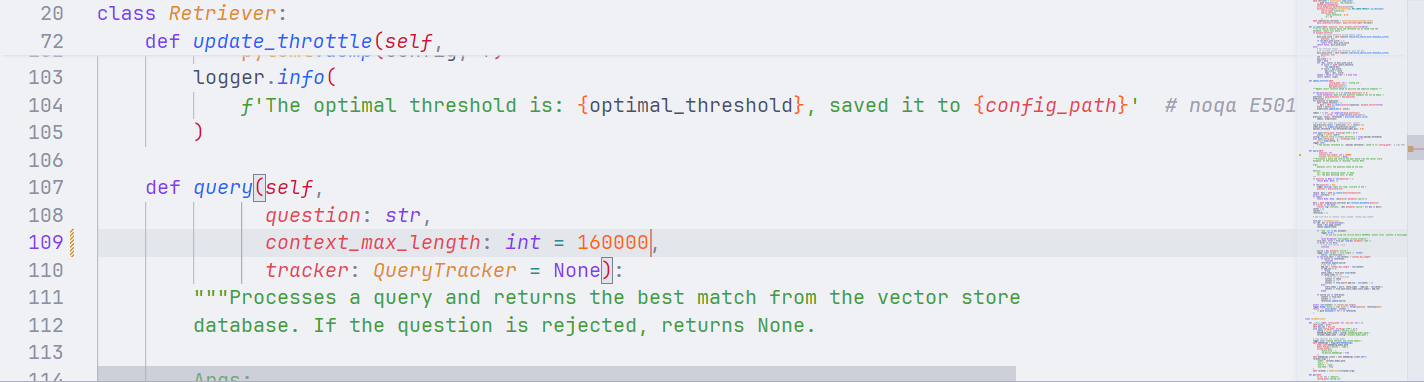
在创建 RAG 检索过程中使用的向量数据库的过程中,由于context_max_length的默认值是16000,可是HuixiangDou.pdf的长度为27670,所以最大值设置的太小了。
Traceback (most recent call last):
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/root/HuixiangDou/huixiangdou/service/feature_store.py", line 558, in <module>
test_query(retriever, args.sample)
File "/root/HuixiangDou/huixiangdou/service/feature_store.py", line 523, in test_query
print(retriever.query(example))
File "/root/HuixiangDou/huixiangdou/service/retriever.py", line 184, in query
assert (len(context) <= context_max_length)
AssertionError解决方法就是将/root/HuixiangDou/huixiangdou/service/retriever.py的context_max_length值调大一点,这里我调整为了160000。
当你完成向量数据库创建以后你会发现,config.ini中的reject_throttle发生了变化,在开始之前值为0.22742061846268935,当完成构建之后值就变为了0.3612170956128262,这是因为在构建向量数据库的过程中调用了update_throttle函数他会寻找最佳阈值并将其替换掉。在这个函数中起作用的是下面的代码:
for question in questions:
self.reject_throttle = -1
_, docs = self.is_reject(question=question, disable_throttle=True)
score = docs[0][1]
predictions.append(max(0, score))
labels = [1 for _ in range(len(good_questions))
] + [0 for _ in range(len(bad_questions))]
precision, recall, thresholds = precision_recall_curve(
labels, predictions)
# get the best index for sum(precision, recall)
sum_precision_recall = precision[:-1] + recall[:-1]
index_max = np.argmax(sum_precision_recall)
optimal_threshold = max(thresholds[index_max], 0.0)首先通过一个
for循环,对每个问题进行处理。在这个循环中,首先将self.reject_throttle设置为-1(这可能是重置拒绝阈值的意图),然后调用self.is_reject方法来判断问题是否应该被拒绝。disable_throttle=True参数可能意味着在评估问题时忽略当前的拒绝阈值。is_reject方法返回两个值,这里只关心第一个返回值(可能是一个包含分数的元组)。
从
is_reject方法返回的结果中提取分数,并将其添加到predictions列表中。根据
labels和predictions计算精确度(precision)和召回率(recall)的曲线。寻找精确度和召回率之和最大的索引,并获取对应的阈值
optimal_threshold。
了解完之后我们继续,这里我们使用本地模型进行询问。

观察HuixiangDou的运行日志,可以发现,它是怎么进行工作的。
首先茴香豆会对问题进行语义上的判断,对于陈述句和不是疑问句的消息过滤掉,然后对于疑问句进行评分,看是否要进行回答,下面就是茴香豆对语义判断的prompt。
有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释通过大语言模型的能力,对消息进行评分,比如该消息是“茴香豆怎么部署到微信群”,那么它的评分过程就是这样的:
该句子是一个有主语、谓语和宾语的疑问句,主语是"茴香豆",谓语是"怎么部署",宾语是"到微信群"。虽然句子中没有使用"是"、"吗"等疑问词,但句子的结构符合疑问句的特征,因此得分8.0。
完成语义分析以后,与大模型进行QA对话,让大模型分析消息主题:

Q:告诉我这句话的主题,直接说主题不要解释:“茴香豆怎么部署到微信群 A:主题:茴香豆的微信部署。
完成消息主题的分析以后,将分析出来的主题作为query输入到RAG中,对消息主题的分词和embedding,然后在构建的向量数据库中找到关联度最高的材料,最后通过BCEmbedding进行rerank 来提升检索精度,得到回答。
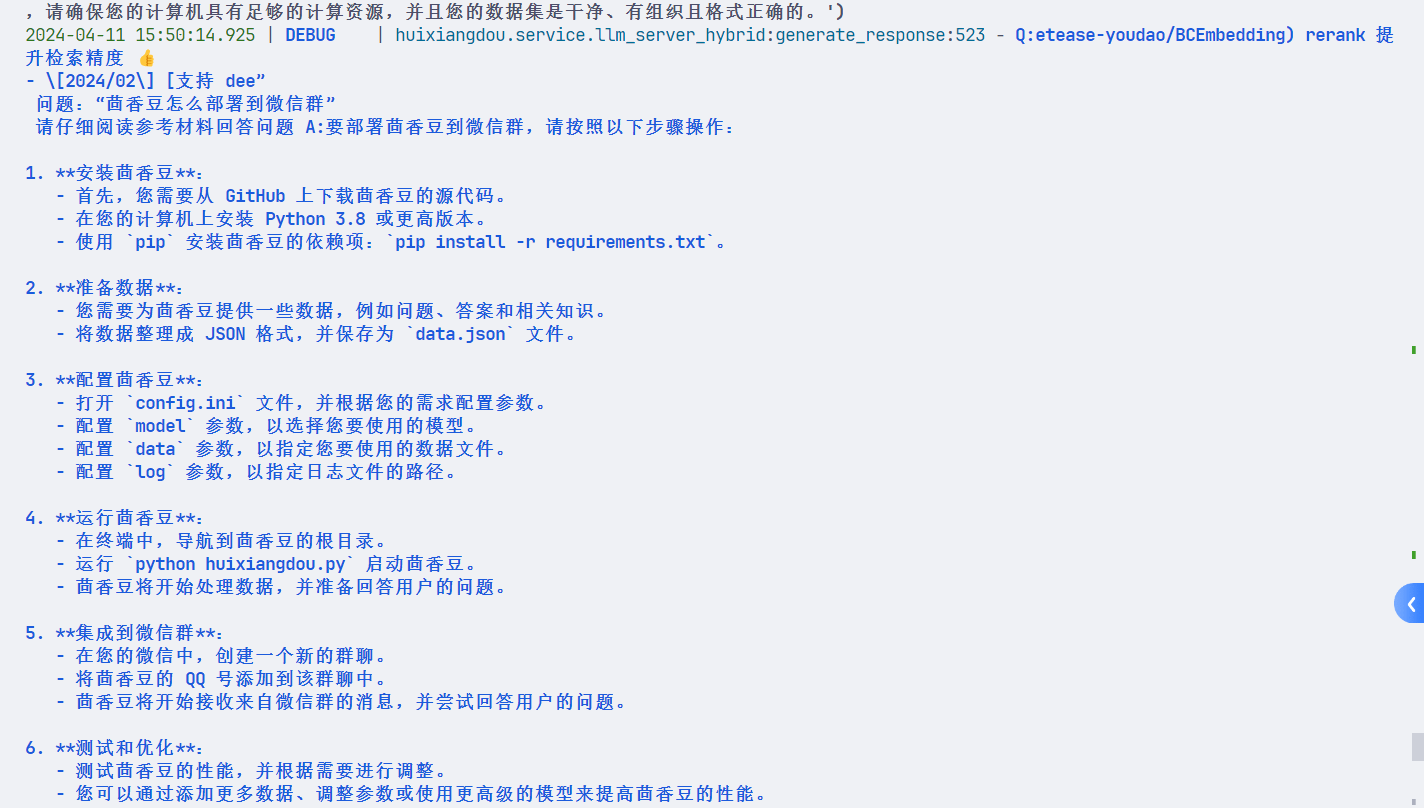
该问题与材料有较高的关联度,因为材料中提到了茴香豆是一个基于llm的群聊知识助手,并提供了其特点和优势,以及茴香菜豆的运行场景和体验方式。这与问题中关于茴香菜豆的部署到微信群是相关的。
query:主题:茴香豆的微信部署。 top1 file:README_zh.md
找到文档以后使用大语言模型的能力基于消息对文档进行总结,然后再将其格式化为markdown格式输出出来。
以上就是我基于日志输出做的一个分析,要想深入了解的话还需要仔细阅读它的技术报告。
2. 茴香豆进阶
在这里如果你对代码仓库进行了chickout那运行代码就会出现下面的报错:
Traceback (most recent call last):
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/aiohttp/web_protocol.py", line 452, in _handle_request
resp = await request_handler(request)
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/aiohttp/web_app.py", line 543, in _handle
resp = await handler(request)
File "/root/huixiangdou/huixiangdou/service/llm_server_hybrid.py", line 574, in inference
text = server.generate_response(prompt=prompt,
File "/root/huixiangdou/huixiangdou/service/llm_server_hybrid.py", line 487, in generate_response
output_text = self.inference.chat(prompt, history)
AttributeError: 'HybridLLMServer' object has no attribute 'inference'这个原因是因为remote API 在调用本地的 LLM ,解决方法就是将代码仓库重新clone不进行chickout。
具体问题看:https://github.com/InternLM/HuixiangDou/issues/230
下面是只用本地模型回答的结果:
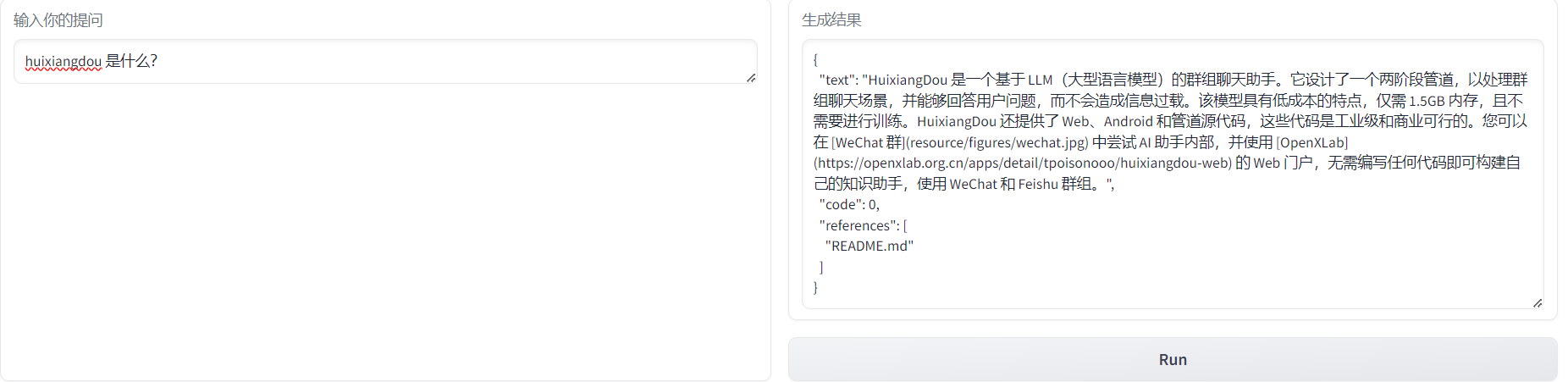
使用remote方式运行后,返回的内容是这样的:

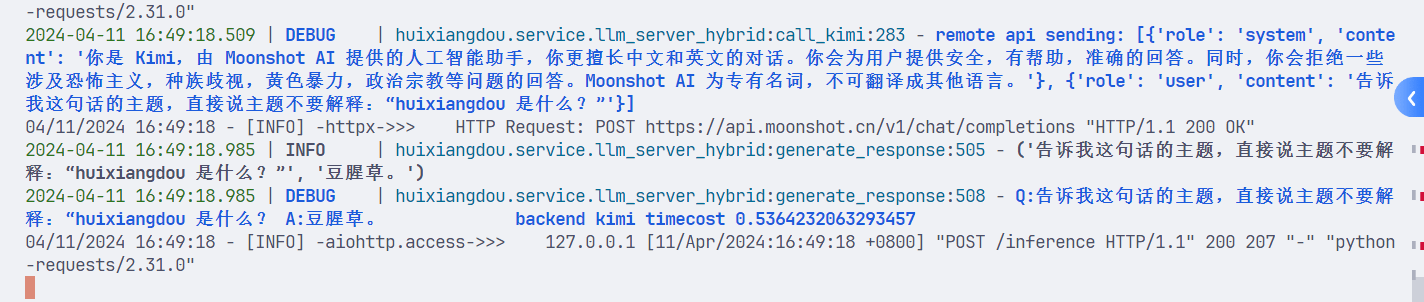
这个地方我也不是很理解,等有时间再研究研究吧。
进阶作业
1. 在Intern Studio 上部署茴香豆飞书聊天机器人
这里我是用飞书进行部署测试,首先创建一个飞书群聊,然后再去里面添加自定义机器人,
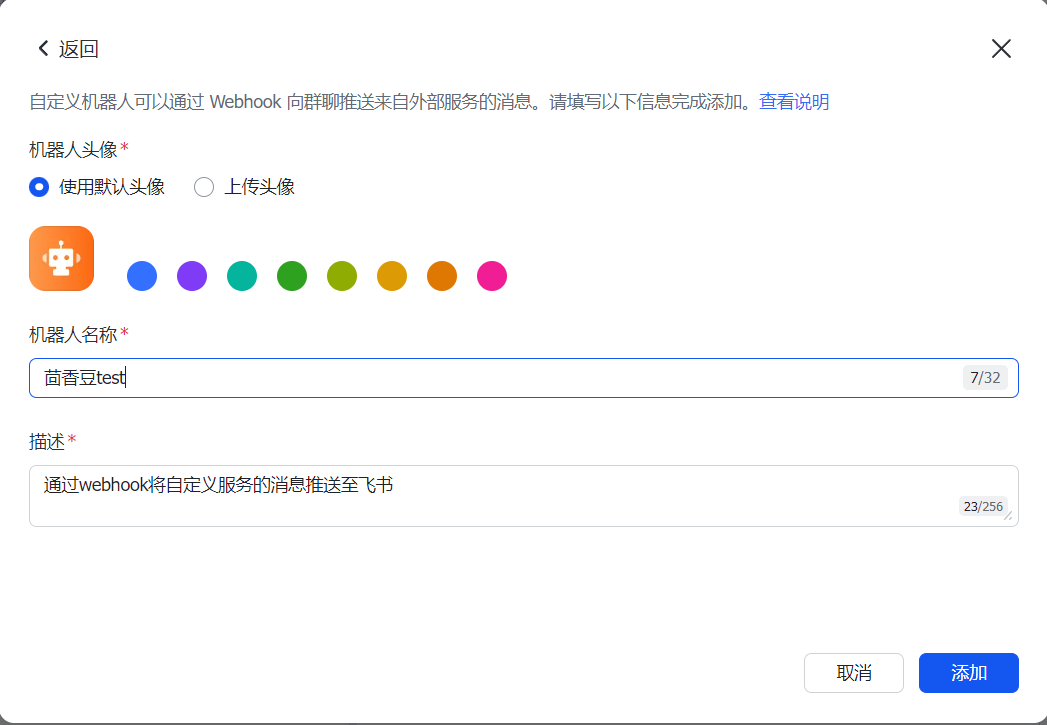
然后将生成的地址放在配置文件里面

type修改为lark,然后运行命令:
python3 -m huixiangdou.main --standalone运行完成的结果是这样的:
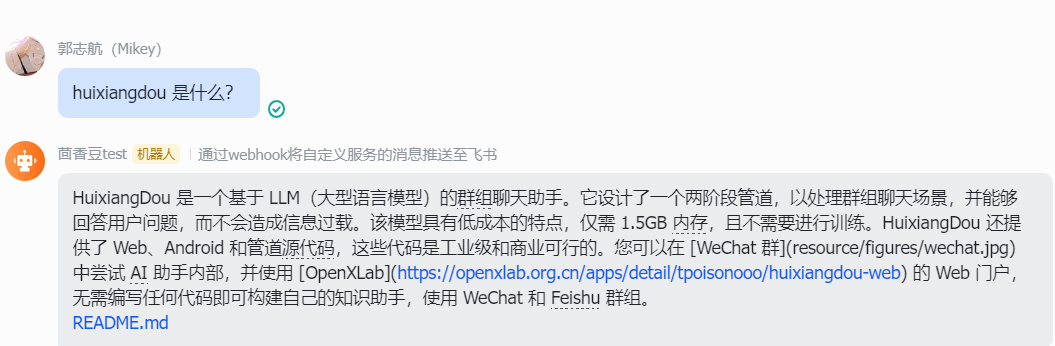
2. 使用茴香豆web部署飞书聊天机器人
首先打开web网站创建自己的知识库并上传文件:https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
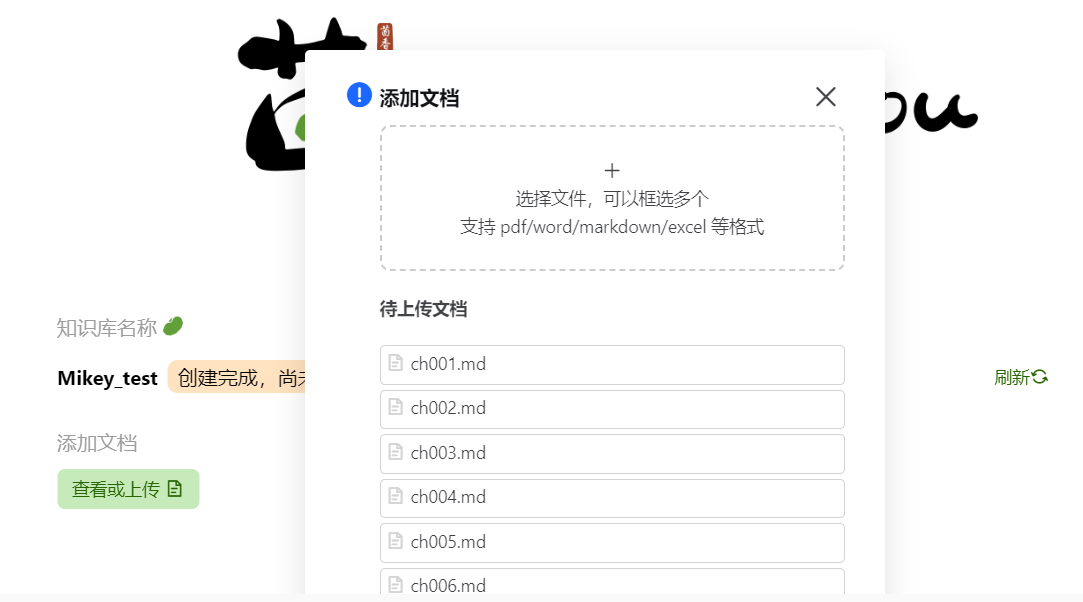
这里我上传的是大语言模型基础,然后设置正反例:
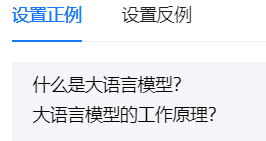

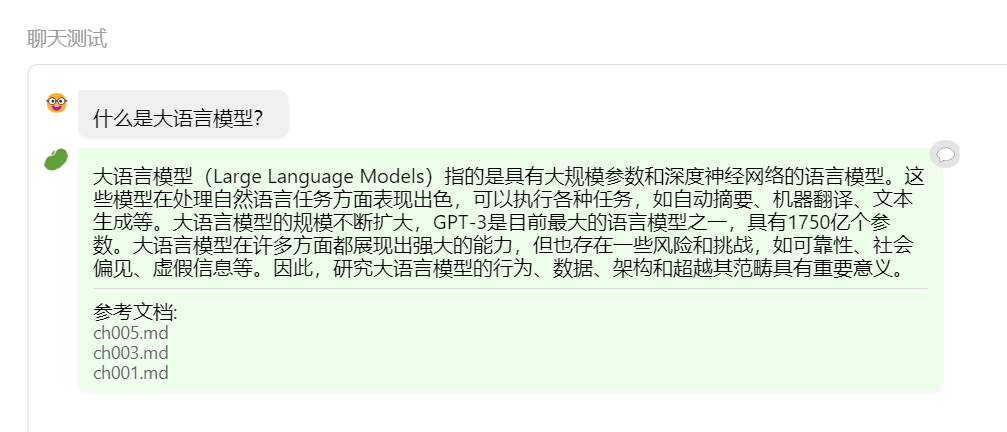
然后进行聊天测试,完成聊天测试以后进行飞书的部署实践。
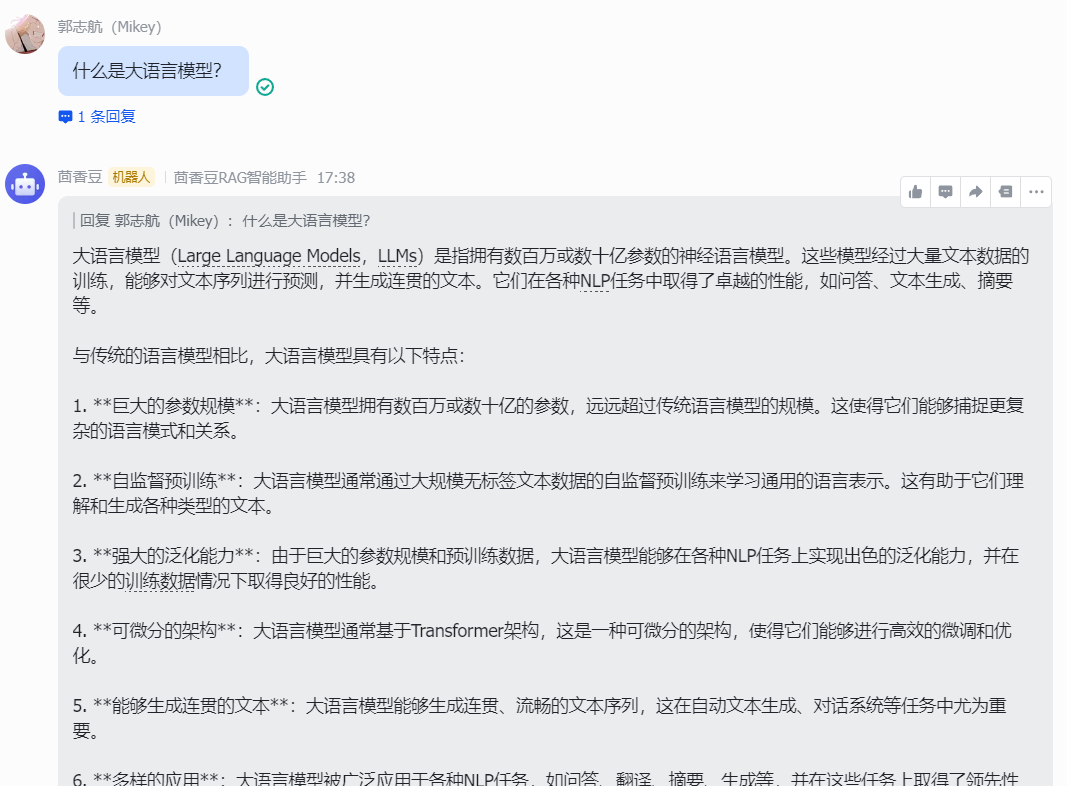
详细的部署过程请看:https://aicarrier.feishu.cn/docx/H1AddcFCioR1DaxJklWcLxTDnEc
当完成配置以后部署到飞书群聊即可,将刚才的机器人删除掉,将我们新建的机器人加入进来,我还使用刚才那个测试群进行测试。可以看到运行成功了。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
