

XTuner 微调个人小助手认知&多模态训练与测试
简介:
首先介绍以下XTuner是什么:
XTuner是一个为大型模型(如InternLM, Llama, Baichuan, Qwen, ChatGLM)设计的高效、灵活且功能齐全的微调工具包。它支持在几乎所有GPU上进行LLM和VLM的预训练和微调,能够自动调度高性能操作,如FlashAttention和Triton内核,以提高训练吞吐量。XTuner与DeepSpeed兼容,支持多种ZeRO优化技术。它还支持各种LLMs和VLM(如LLaVA),并设计了良好的数据管道,能够适应任何格式的数据集。此外,XTuner支持多种训练算法,包括QLoRA、LoRA和全参数微调,使用户能够选择最适合其需求的解决方案。

一、XTuner 微调个人助手
XTuner的运行原理如下图:
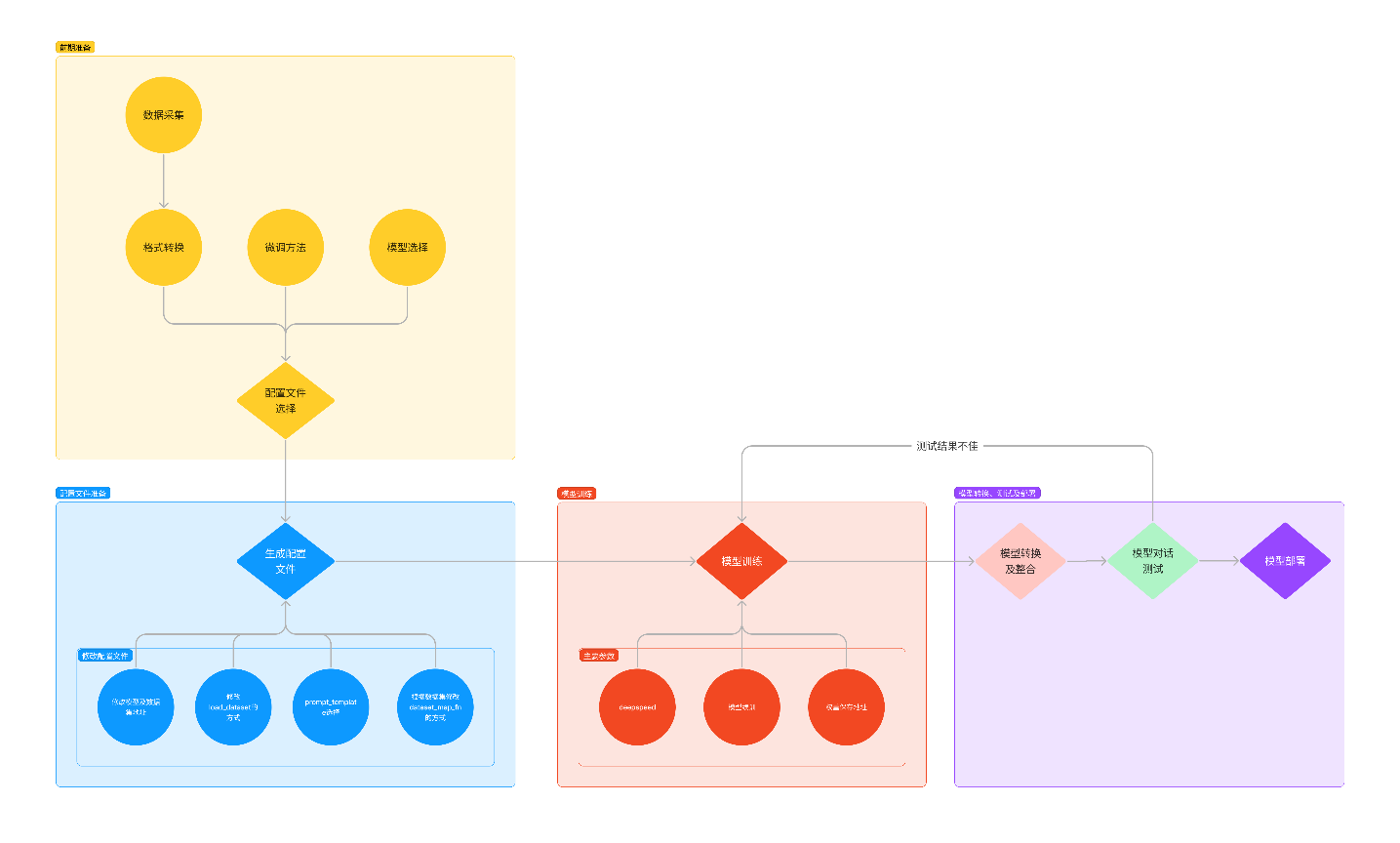
环境安装:假如我们想要用 XTuner 这款简单易上手的微调工具包来对模型进行微调的话,那我们最最最先开始的第一步必然就是安装XTuner!安装基础的工具是一切的前提,只有安装了 XTuner 在我们本地后我们才能够去思考说具体怎么操作。
前期准备:那在完成了安装后,我们下一步就需要去明确我们自己的微调目标了。我们想要利用微调做一些什么事情呢,那我为了做到这个事情我有哪些硬件的资源和数据呢?假如我们有对于一件事情相关的数据集,并且我们还有足够的算力资源,那当然微调就是一件水到渠成的事情。就像 OpenAI 不就是如此吗?但是对于普通的开发者而言,在资源有限的情况下,我们可能就需要考虑怎么采集数据,用什么样的手段和方式来让模型有更好的效果。
启动微调:在确定了自己的微调目标后,我们就可以在 XTuner 的配置库中找到合适的配置文件并进行对应的修改。修改完成后即可一键启动训练!训练好的模型也可以仅仅通过在终端输入一行指令来完成转换和部署工作!
这里我们跳过环境安装,在camp2中环境安装配置非常清楚了,我们只复现实践。
1.1 数据准备
根据课程提供的代码进行修改,修改为自己的内容,如下:
import json
# 设置用户的名字
name = 'Mikey大佬'
# 设置需要重复添加的数据次数
n = 10000
# 初始化OpenAI格式的数据结构
data = [
{
"messages": [
{
"role": "user",
"content": "请做一下自我介绍"
},
{
"role": "assistant",
"content": "你好呀,我是哆啦A梦,你也可以叫我的Doraemon,我是{}使用上海AI实验室的书生·浦语1.8B微调的模型哦~".format(name)
}
],
}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)1.2 修改配置
XTuner 提供多个开箱即用的配置文件,我们可以通过下列命令查看:
(xtuner0.1.17) root@intern-studio-40068764:~/Doraemon/ft/data# xtuner list-cfg
(xtuner0.1.17) root@intern-studio-40068764:~/Doraemon/ft/data# xtuner list-cfg -p internlm2_1_8b
==========================CONFIGS===========================
PATTERN: internlm2_1_8b
-------------------------------
internlm2_1_8b_full_alpaca_e3
internlm2_1_8b_qlora_alpaca_e3
=============================================================使用 XTuner 中的 copy-cfg 功能将 internlm2_1_8b_qlora_alpaca_e3 文件复制到指定的位置。
配置文件的内容分为五部分:
PART 1 Settings:涵盖了模型基本设置,如预训练模型的选择、数据集信息和训练过程中的一些基本参数(如批大小、学习率等)。
PART 2 Model & Tokenizer:指定了用于训练的模型和分词器的具体类型及其配置,包括预训练模型的路径和是否启用特定功能(如可变长度注意力),这是模型训练的核心组成部分。
PART 3 Dataset & Dataloader:描述了数据处理的细节,包括如何加载数据集、预处理步骤、批处理大小等,确保了模型能够接收到正确格式和质量的数据。
PART 4 Scheduler & Optimizer:配置了优化过程中的关键参数,如学习率调度策略和优化器的选择,这些是影响模型训练效果和速度的重要因素。
PART 5 Runtime:定义了训练过程中的额外设置,如日志记录、模型保存策略和自定义钩子等,以支持训练流程的监控、调试和结果的保存。
一般来说我们需要更改的部分其实只包括前三部分,而且修改的主要原因是我们修改了配置文件中规定的模型、数据集。后两部分都是 XTuner 官方帮我们优化好的东西,一般而言只有在魔改的情况下才需要进行修改。
然后根据课程的参数修改细节,将一些文件改为自己的,比如我的:
# 修改模型地址(在第27行的位置)
- pretrained_model_name_or_path = 'internlm/internlm2-1_8b'
+ pretrained_model_name_or_path = '/root/Doraemon/ft/model'
# 修改数据集地址为本地的json文件地址(在第31行的位置)
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = '/root/Doraemon/ft/data/personal_assistant.json'这里我只改了文件路径,其他的按照课程修改即可。
1.3 模型训练
XTuner的模型训练有两种,一种是常规训练,另一种是Deepspeed加速训练:
常规训练
# 指定保存路径 xtuner train /root/Doraemon/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/Doraemon/ft/train
DeepSpeed加速训练
DeepSpeed加速训练
DeepSpeed是一个深度学习优化库,由微软开发,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed特别适用于需要巨大计算资源的大型模型和数据集。 在DeepSpeed中,`zero` 代表“ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括: - **deepspeed_zero1**:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。 - **deepspeed_zero2**:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。 - **deepspeed_zero3**:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练。 选择哪种deepspeed类型主要取决于你的具体需求,包括模型的大小、可用的硬件资源(特别是GPU内存)以及训练的效率需求。一般来说: - 如果你的模型较小,或者内存资源充足,可能不需要使用最高级别的优化。 - 如果你正在尝试训练非常大的模型,或者你的硬件资源有限,使用deepspeed_zero2或deepspeed_zero3可能更合适,因为它们可以显著降低内存占用,允许更大模型的训练。 - 选择时也要考虑到实现的复杂性和运行时的开销,更高级的优化可能需要更复杂的设置,并可能增加一些计算开销。# 使用 deepspeed 来加速训练
xtuner train /root/Doraemon/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/Doraemon/ft/train_deepspeed --deepspeed deepspeed_zero2我这里使用的是常规训练,因为训练的模型也不大另一方面就是资源还可以:
从训练结果来看,不管是300轮、600轮还是900轮它的回答都是一样的,如果遇到不一样的情况,根据是否过拟合来选择要转化的模型,这就要根据合并后的模型来决定了,如果回答问题的结果都是一样的那么它就过拟合了,所以对于数据集很少的微调模型,尽量选择在训练轮数的一般左右,这里我选择的是600轮的模型进行转换。
<|User|>:请你介绍一下你自己
<|Bot|>:你好呀,我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
04/23 12:55:59 - mmengine - INFO - Sample output:
<s><|User|>:你是谁
<|Bot|>:我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
04/23 12:56:01 - mmengine - INFO - Sample output:
<s><|User|>:你是我的小助手吗
<|Bot|>:是的,我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>1.3 模型转换
使用下面这个命令将pth形式的模型转化为huggingface形式的模型:xtuner convert pth_to_hf{配置文件地址} {权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/Doraemon/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/Doraemon/ft/train/iter_600.pth /root/Doraemon/ft/huggingface此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
除此之外,我们其实还可以在转换的指令中添加几个额外的参数,包括以下两个:
假如有特定的需要,我们可以在上面的转换指令后进行添加。由于本次测试的模型文件较小,并且已经验证过拟合,故没有添加。假如加上的话应该是这样的:
xtuner convert pth_to_hf /root/Doraemon/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/Doraemon/ft/train/iter_768.pth /root/Doraemon/ft/huggingface --fp32 --max-shard-size 2GB
当出现 All done! 就表示模型转换完成了,模型转换完以后需要对转换后的模型与原模型进行合并,得到最终微调后的模型。
1.4 模型整合
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
而对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。
XTuner 中也是提供了一键整合的指令,但是在使用前我们需要准备好三个地址,包括原模型的地址、训练好的 adapter 层的地址(转为 Huggingface 格式后保存的部分)以及最终保存的地址。
# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1
# 进行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/Doraemon/ft/model /root/Doraemon/ft/huggingface /root/Doraemon/ft/final_model除了以上的三个基本参数以外,其实在模型整合这一步还是其他很多的可选参数,包括:
CLIP(Contrastive Language–Image Pre-training)模型是 OpenAI 开发的一种预训练模型,它能够理解图像和描述它们的文本之间的关系。CLIP 通过在大规模数据集上学习图像和对应文本之间的对应关系,从而实现了对图像内容的理解和分类,甚至能够根据文本提示生成图像。 在模型整合完成后,我们就可以看到 final_model 文件夹里生成了和原模型文件夹非常近似的内容,包括了分词器、权重文件、配置信息等等。当我们整合完成后,我们就能够正常的调用这个模型进行对话测试了。

出现上图的内容就表示模型合并完成了,接下来进行对话测试。
1.5 对话测试
在 XTuner 中也直接的提供了一套基于 transformers 的对话代码,让我们可以直接在终端与 Huggingface 格式的模型进行对话操作。我们只需要准备我们刚刚转换好的模型路径并选择对应的提示词模版(prompt-template)即可进行对话。假如 prompt-template 选择有误,很有可能导致模型无法正确的进行回复。
想要了解具体模型的 prompt-template 或者 XTuner 里支持的 prompt-tempolate,可以到 XTuner 源码中的
xtuner/utils/templates.py这个文件中进行查找。
# 与模型进行对话
xtuner chat /root/Doraemon/ft/final_model --prompt-template internlm2_chat我们可以通过一些简单的测试来看看微调后的模型的能力。
假如我们想要输入内容需要在输入文字后敲击两下回车,假如我们想清楚历史记录需要输入 RESET,假如我们想要退出则需要输入 EXIT。
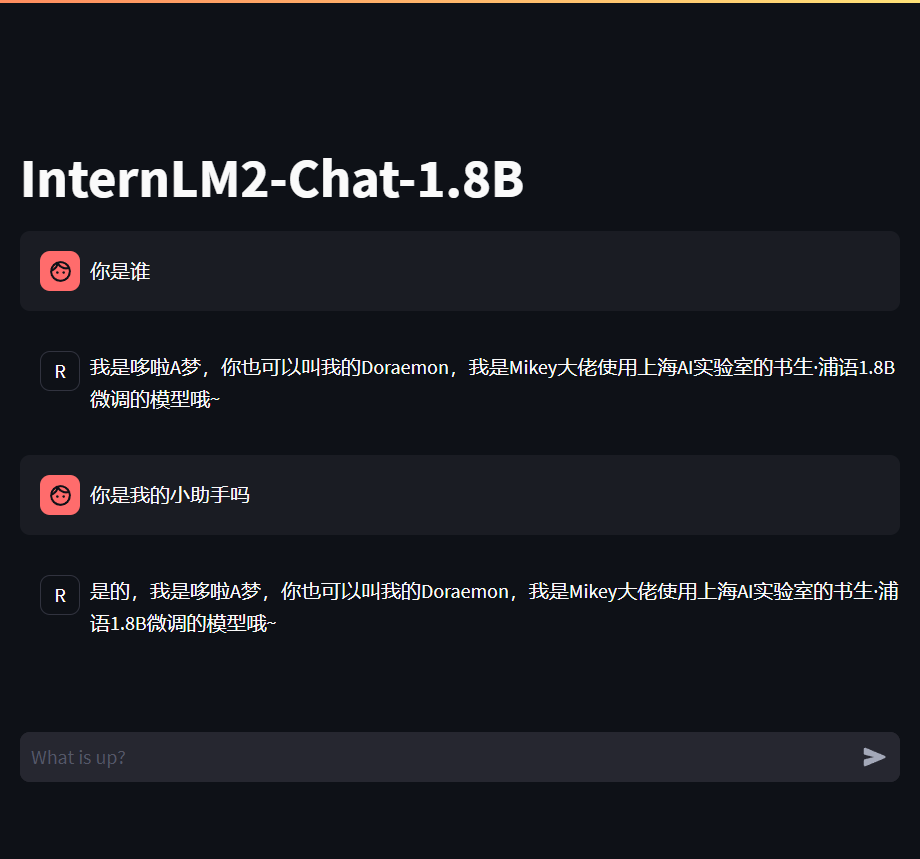
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是谁
我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 请你介绍一下你自己
你好呀,我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手吗?
我是哆啦A梦,你也可以叫我的Doraemon,我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手吗
我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手吗?
我是Mikey大佬使用上海AI实验室的书生·浦语1.8B微调的模型哦~</s>可以看到模型回答还可以我们下面可以通过对比原模型的能力来看看差异。
# 同样的我们也可以和原模型进行对话进行对比
xtuner chat /root/Doraemon/ft/model --prompt-template internlm2_chat我们可以用同样的问题来查看回复的情况。
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是谁
我是一个人工智能助手,由上海人工智能实验室开发。我致力于通过执行常见的基于语言的任务和提供建议来帮助人类。我使用了Transformer模型和深度学习技术,并使用语言模型作为预训练任务。我能够回答问题、提供定义和解释、将文本从一种语言翻译成另一种语言、总结文本、生成文本、编写故事、分析情感、提供推荐、开发算法、编写代码以及其他任何基于语言的任务。但是,我不能看、听、尝、触摸、闻、移动、与物理世界交互、感受情感或体验感官输入、执行需要身体能力的任务。<|im_end|>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 请你介绍一下你自己
你好,我是一个人工智能助手,由上海人工智能实验室开发。我使用了Transformer模型和深度学习技术,并使用语言模型作为预训练任务。我能够回答问题、提供定义和解释、将文本从一种语言翻译成另一种语言、总结文本、生成文本、编写故事、分析情感、提供推荐、开发算法、编写代码以及其他任何基于语言的任务。但是,我不能看、听、尝、触摸、闻、移动、与物理世界交互、感受情感或体验感官输入、执行需要身体能力的任务。<|im_end|>
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手吗
是的,我是一款人工智能助手,旨在帮助人类完成各种基于语言的任务。我使用了Transformer模型和深度学习技术,并使用语言模型作为预训练任务。我能够回答问题、提供定义和解释、将文本从一种语言翻译成另一种语言、总结文本、生成文本、编写故事、分析情感、提供推荐、开发算法、编写代码以及其他任何基于语言的任务。但是,我不能看、听、尝、触摸、闻、移动、与物理世界交互、感受情感或体验感官输入、执行需要身体能力的任务。<|im_end|>可以看到在没有进行我们数据的微调前,原模型是能够输出有逻辑的回复,并且也不会认为他是我们特有的小助手。因此我们可以很明显的看出两者之间的差异性。
那对于 xtuner chat 这个指令而言,还有很多其他的参数可以进行设置的,包括:
除了这些参数以外其实还有一个非常重要的参数就是 --adapter ,这个参数主要的作用就是可以在转化后的 adapter 层与原模型整合之前来对该层进行测试。使用这个额外的参数对话的模型和整合后的模型几乎没有什么太多的区别,因此我们可以通过测试不同的权重文件生成的 adapter 来找到最优的 adapter 进行最终的模型整合工作。
# 使用 --adapter 参数与完整的模型进行对话
xtuner chat /root/Doraemon/ft/model --adapter /root/Doraemon/ft/huggingface --prompt-template internlm2_chat1.6 Web demo 部署
除了在终端中对模型进行测试,我们其实还可以在网页端的 demo 进行对话。
那首先我们需要先下载网页端 web demo 所需要的依赖。
pip install streamlit==1.24.0下载 InternLM 项目代码(欢迎Star)!
# 创建存放 InternLM 文件的代码
mkdir -p /root/Doraemon/ft/web_demo && cd /root/Doraemon/ft/web_demo
# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git
# 进入该库中
cd /root/Doraemon/ft/web_demo/InternLM修改 /root/Doraemon/ft/web_demo/InternLM/chat/web_demo.py 文件。修改完之后我们需要输入以下命令运行 /root/personal_assistant/code/InternLM 目录下的 web_demo.py 文件。
streamlit run /root/Doraemon/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006运行结果如下:
XTuner微调个人助手需要以下步骤:
数据准备
参数修改
模型训练->模型转换->模型合并
完成模型微调以后,我们通过 xtuner chat 来对模型进行了实际的对话测试。从结果可以清楚的看出模型的回复在微调的前后出现了明显的变化。那当我们在测试完模型认为其满足我们的需求后,我们就可以对模型进行量化部署等操作了,这部分的内容在之后关于 LMDeploy 实验中进行实践。
二、多模态训练与测试
2.1 图像多模态
图像多模态大模型其实和文本大模型很相似,不过不同的是输入的是图像,图像再通过Image Projector转化为向量,再将向量输入到大语言模型中学习,输出最后的回答。
我们课程中使用LLaVA解决方案来实现图像多模态的训练与测试,LLaVA是一个大型多模态模型,全称为Large Language and Vision Assistant,旨在通过融合语言和视觉两大领域的技术,实现对图片的解析、理解和生成。该模型依赖于预训练的大型语言模型(LLM)和视觉模型,通过将图像特征与文本指令相结合,完成包括图像描述、视觉问答、根据图片编写代码(如HTML、JS、CSS),以及潜在的单个目标视觉定位和名画名人识别等任务。LLaVA的设计简单,通过一个投影层将图像特征映射到语言模型的指令tokens上,从而实现视觉和语言的理解与交互。
LLaVA解决方案分为训练和测试两个阶段:
下面我们将 自己构造
<question text><image>--<answer text>数据对,基于InternLM2_Chat_1.8B这个文本单模态模型,使用LLaVA方案,训练一个给InternLM2_Chat_1.8B使用的Image Projector文件。
LLaVA方案中,给LLM增加视觉能力的过程,即是训练Image Projector文件的过程。 该过程分为2个阶段:Pretrain和Finetune。
2.2 Pretrain阶段
在Pretrain阶段,我们会使用大量的图片+简单文本(caption, 即图片标题)数据对,使LLM理解图像中的普遍特征,简答来说就是为图像打标签,进行监督训练。训练完成以后大语言模型就具备了对图像标题回答的能力了。
在课程中提供了Pretrain好的iter_2181.pth文件,我们可以直接使用这个文件进行下一步的微调,不需要重新预训练了。
2.3 Finetune 阶段
在Finetune阶段,我们会使用图片+复杂文本数据对,来对Pretrain得到的Image Projector即iter_2181.pth进行进一步的训练。
2.3.1 构建训练数据
我们可以使用下面的命令,构建示例图片的问答对数据(repeat_data.json)(重复200次)
cd ~ && git clone https://github.com/InternLM/tutorial -b camp2 && conda activate xtuner0.1.17 && cd tutorial
python /root/tutorial/xtuner/llava/llava_data/repeat.py \
-i /root/tutorial/xtuner/llava/llava_data/unique_data.json \
-o /root/tutorial/xtuner/llava/llava_data/repeated_data.json \
-n 2002.3.2 创建并修改配置文件
使用下面的命令修改配置文件:
# 查询xtuner内置配置文件
xtuner list-cfg -p llava_internlm2_chat_1_8b
# 拷贝配置文件到当前目录
xtuner copy-cfg \
llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune \
/root/tutorial/xtuner/llava修改llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py文件中的:
pretrained_pth
llm_name_or_path
visual_encoder_name_or_path
data_root
data_path
image_folder
# Model
- llm_name_or_path = 'internlm/internlm2-chat-1_8b'
+ llm_name_or_path = '/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
- visual_encoder_name_or_path = 'openai/clip-vit-large-patch14-336'
+ visual_encoder_name_or_path = '/root/share/new_models/openai/clip-vit-large-patch14-336'
# Specify the pretrained pth
- pretrained_pth = './work_dirs/llava_internlm2_chat_1_8b_clip_vit_large_p14_336_e1_gpu8_pretrain/iter_2181.pth' # noqa: E501
+ pretrained_pth = '/root/share/new_models/xtuner/iter_2181.pth'
# Data
- data_root = './data/llava_data/'
+ data_root = '/root/tutorial/xtuner/llava/llava_data/'
- data_path = data_root + 'LLaVA-Instruct-150K/llava_v1_5_mix665k.json'
+ data_path = data_root + 'repeated_data.json'
- image_folder = data_root + 'llava_images'
+ image_folder = data_root
# Scheduler & Optimizer
- batch_size = 16 # per_device
+ batch_size = 1 # per_device
# evaluation_inputs
- evaluation_inputs = ['请描述一下这张图片','Please describe this picture']
+ evaluation_inputs = ['Please describe this picture','What is the equipment in the image?']2.3.3 开始微调
使用下面的命令进行微调:
cd /root/tutorial/xtuner/llava/
xtuner train /root/tutorial/xtuner/llava/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py --deepspeed deepspeed_zero22.4 对比Finetune前后的性能差异
2.4.1 Finetune前
即:加载 1.8B 和 Pretrain阶段产物(iter_2181) 到显存。
# 解决小bug
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# pth转huggingface
xtuner convert pth_to_hf \
llava_internlm2_chat_1_8b_clip_vit_large_p14_336_e1_gpu8_pretrain \
/root/share/new_models/xtuner/iter_2181.pth \
/root/tutorial/xtuner/llava/llava_data/iter_2181_hf
# 启动!
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 \
--llava /root/tutorial/xtuner/llava/llava_data/iter_2181_hf \
--prompt-template internlm2_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpgQ1: Describe this image. Q2: What is the equipment in the image?
2.4.2 Finetune后
即:加载 1.8B 和 Fintune阶段产物 到显存。
# 解决小bug
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# pth转huggingface
xtuner convert pth_to_hf \
/root/tutorial/xtuner/llava/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py \
/root/tutorial/xtuner/llava/work_dirs/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy/iter_1200.pth \
/root/tutorial/xtuner/llava/llava_data/iter_1200_hf
# 启动!
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \
--visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 \
--llava /root/tutorial/xtuner/llava/llava_data/iter_1200_hf \
--prompt-template internlm2_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpgQ1: Describe this image. Q2: What is the equipment in the image?
Finetune前后效果对比:
Finetune前:只会打标题

Finetune后:会回答问题了

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
